

参考资料:
前言
本文基于Windows11系统搭建,部署过程可能和实际情况存在出入,仅供参考
不适用于Linux,Linux用户请参考其他文章
最低系统版本为Windows10,否则无法部署
推荐Windows10 22H2(19045)或更高系统版本,该版本使用WSL2运行Docker,相比Hyper-V运行性能更好
C盘需要预留50GB以上空间,或自行迁移Docker虚拟机位置
RAGFlow本身需要16GB内存,如果还需要本地运行大模型,则推荐在32GB以上的电脑部署
本地搭建流程可分为以下几步:
下载并安装Ollama
配置Ollama,下载并运行Deepseek-R1模型
下载并安装Docker
下载并在Docker中部署RAGflow
配置RAGflow,创建知识库并调用Ollama中的Deepseek-R1模型进行对话
开始部署
安装Ollama
Ollama是一个用于本地运行和管理大语言模型(LLM)的工具,我们利用这个工具在本地运行deepseek R1模型
下载
前往Ollama官网:
点击官网的“Download”按钮
选择Windows平台,再点击“Download for Windows”按钮下载
安装
运行刚刚下载的OllamaSetup.exe,点击“Install”,等待安装程序运行完成
Ollama默认安装在C盘且不可更改路径,需占用磁盘约5GB空间
稍后安装程序会自动退出,并发出通知消息
托盘中出现Ollama的图标则说明安装完成
配置
添加环境变量
安装后还不能直接使用,需要添加两个环境变量
右键“此电脑”,点击属性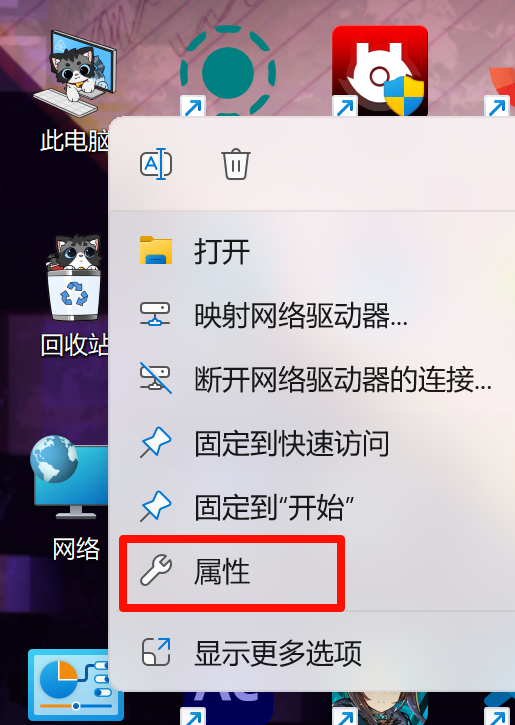
点击“高级系统设置”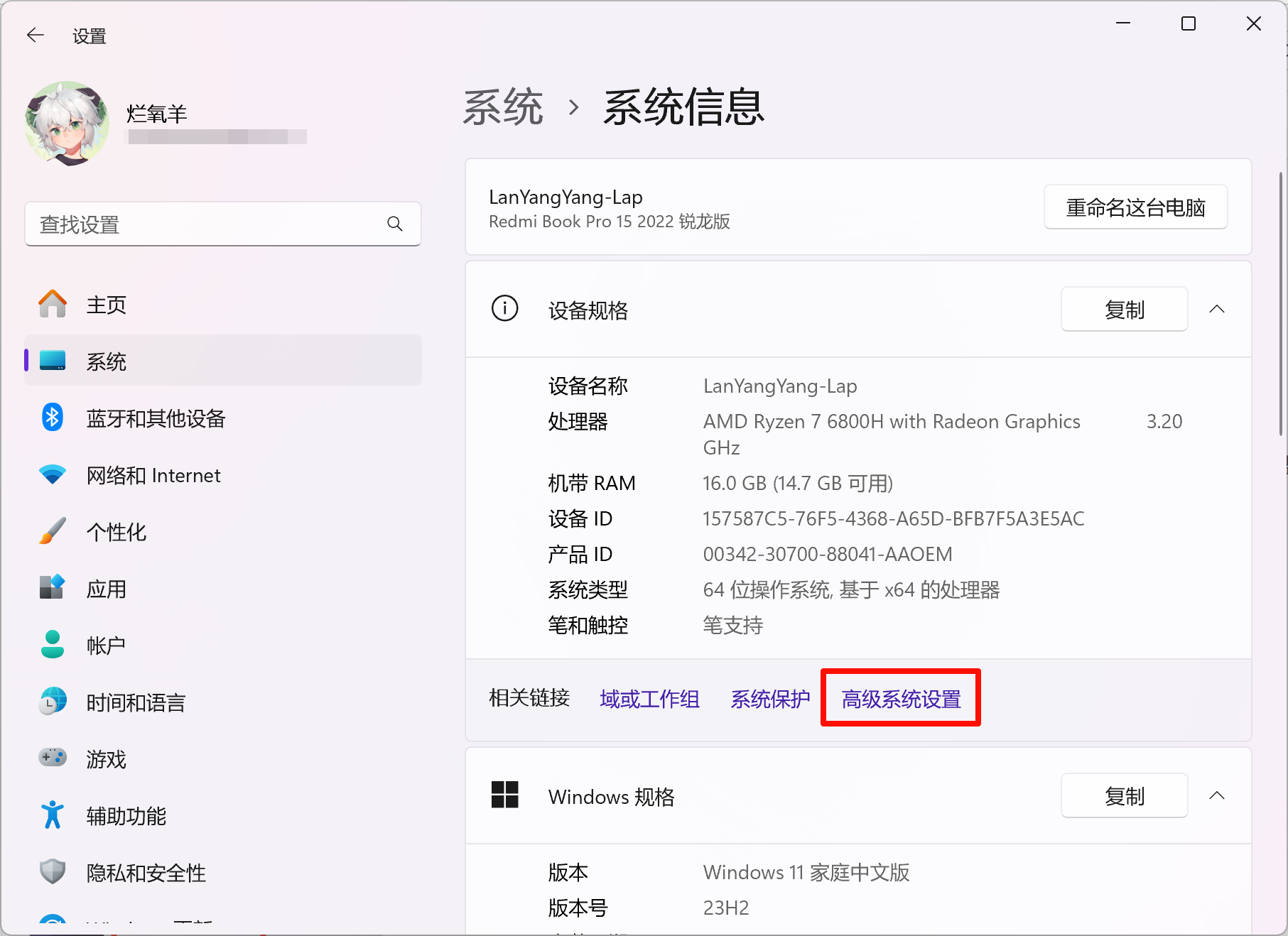
点击“环境变量”
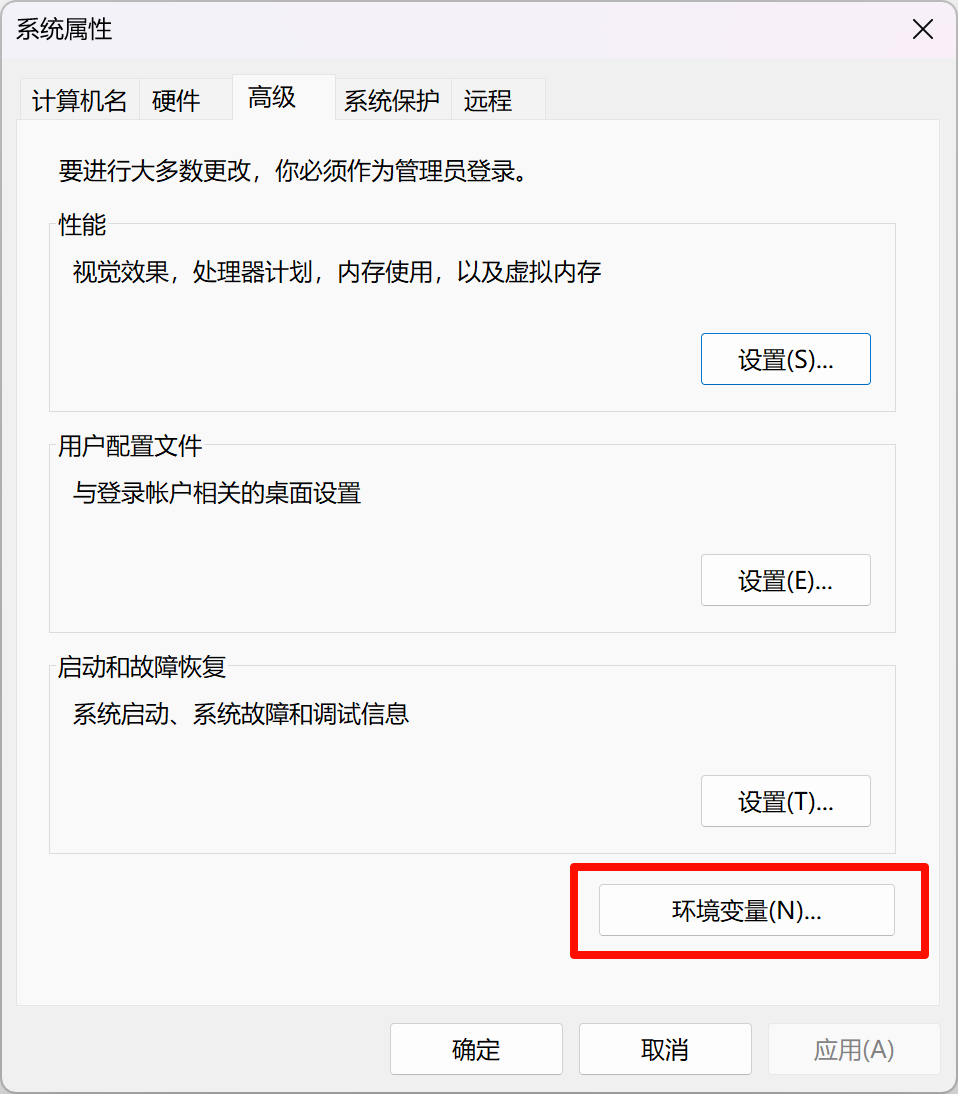
再点击“新建”
新建Ollama_HOST变量,值为0.0.0.0:8080
这个变量修改了Ollama监听的端口,否则RAGflow将无法访问Ollama
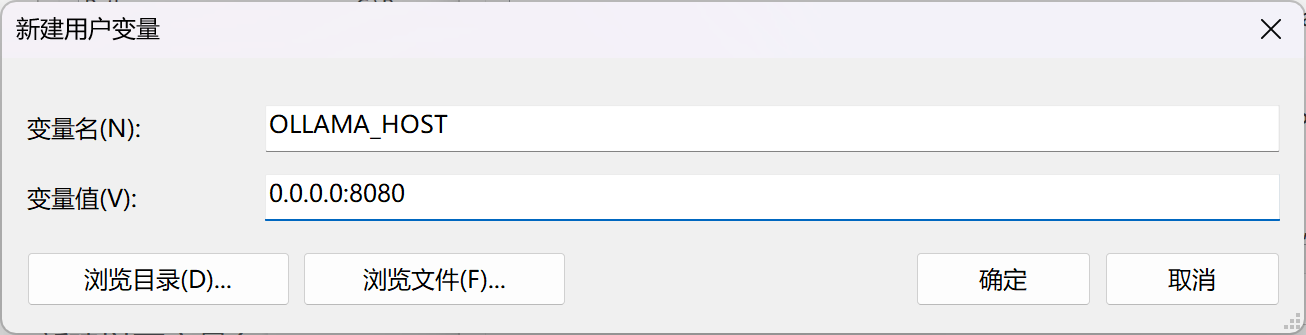
新建Ollama_MODELS变量,值为D:\UserFiles\OllamaModels
这个变量修改了Ollama下载模型的位置,需要自己创建对应的文件夹,不这么做会默认下载到C盘导致C盘爆满
添加完成后需要重启电脑使环境变量生效,重启后会出现防火墙提醒,点击允许
部署模型
模型可以根据需要自行选择,这里以deepseek-r1模型为例
回到Ollama官网:
在上方的搜索框输入deepseek-r1,点击第一个结果
在这个页面可以选择具体的模型大小,此处的b指的是十亿(Billion)参数,比如1.5b代表这个模型有15亿的参数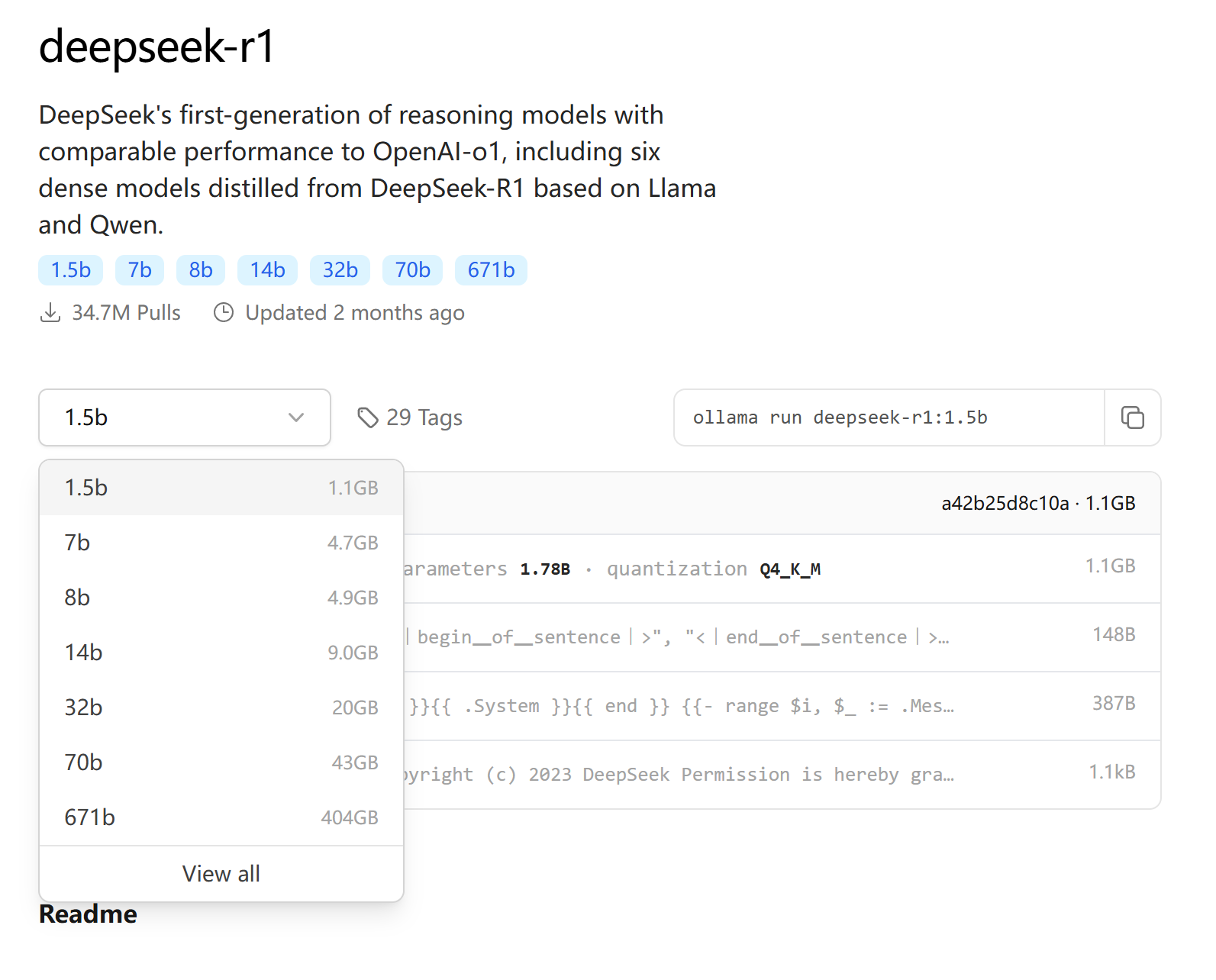
b前面的数字越大模型越“聪明”,但对电脑的性能要求和占用空间也越大
最小的1.5b几乎是个电脑都能运行,最大的671b需要专门的运算阵列才能运行,这里用1.5b模型进行演示
在下拉菜单选择1.5b后,页面右侧会出现命令提示,点击最右边的按钮复制下来
打开命令提示符(CMD),将刚才复制的命令粘贴到窗口,按下回车,Ollama会开始部署deepseek-r1 1.5b模型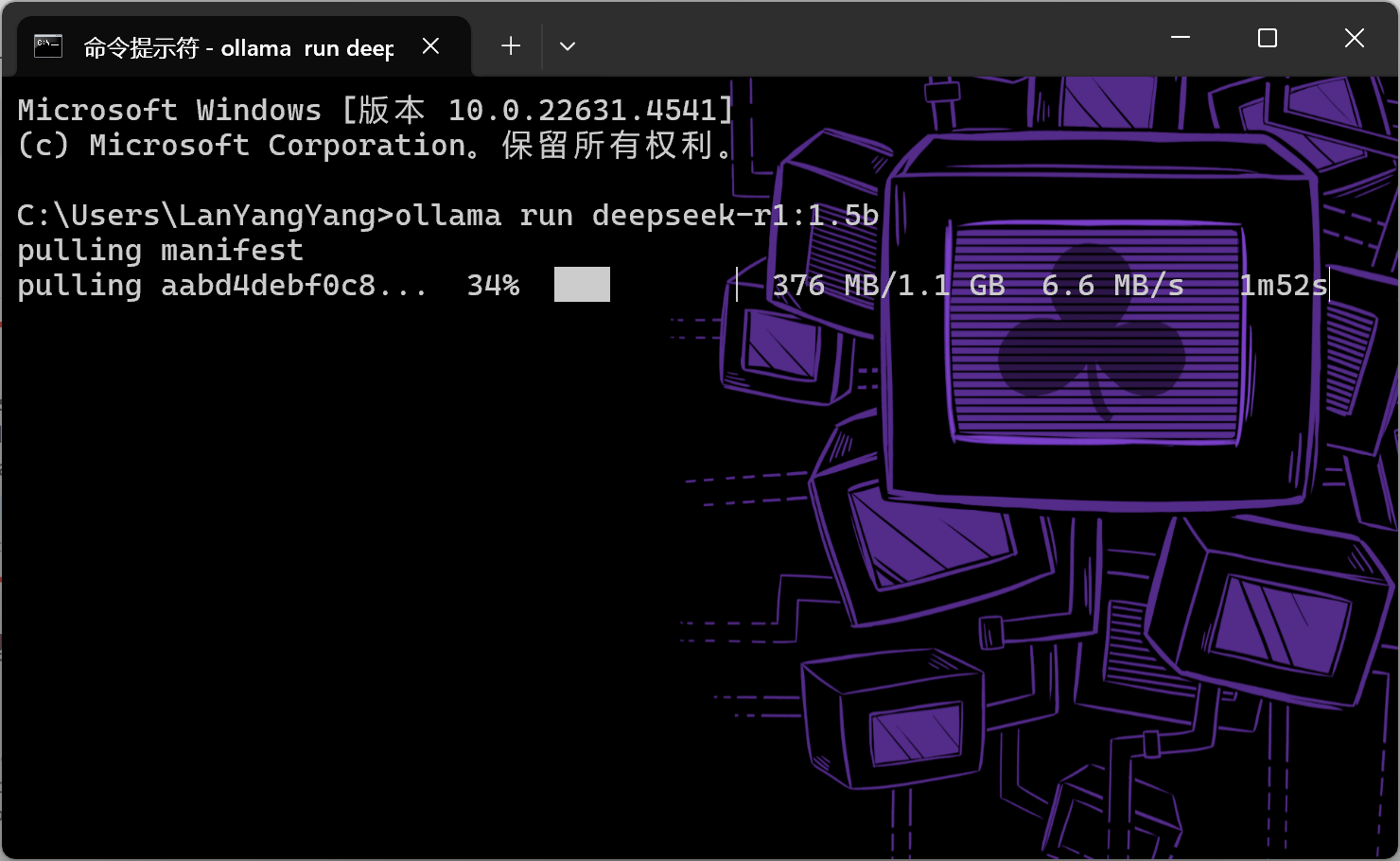
等待一段时间后部署完成,窗口会变为对话窗口,可以在这直接和模型对话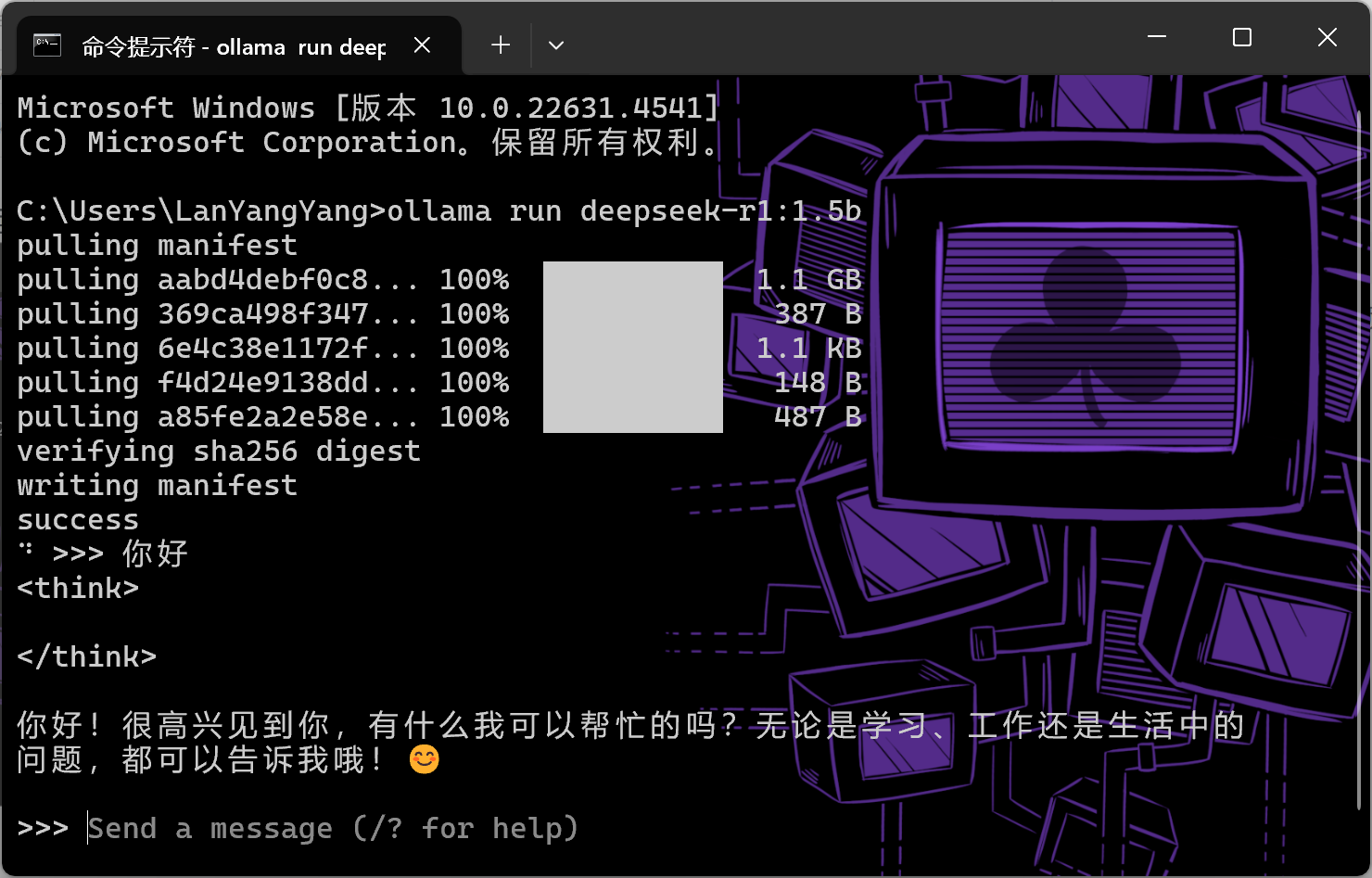
安装Docker(桌面版)
Docker是一个开源的应用容器引擎,利用它我们可以迅速在本地部署RAGflow
开启Hyper-V
Docker需要一个Linux虚拟机作为基础才能运行,因此我们需要开启Hyper-V功能
首先需要在电脑的Bios开启虚拟化选项,各个厂商都有所不同,建议自行搜索
然后打开控制面板,进入“程序”板块
找到“启用或关闭Windows功能”
打开“虚拟机平台”、“适用于Linux的Windows子系统”,点击确定后等待添加功能,然后重启电脑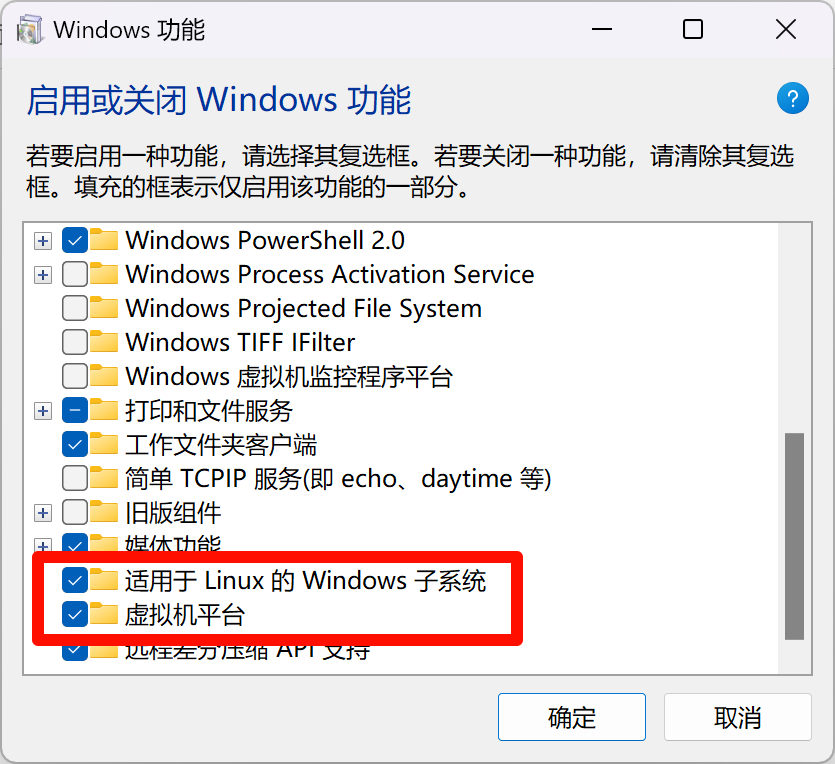
更新WSL
在较新的系统版本,Docker会选用WSL作为基础,但需要使用WSL2,而系统预装的可能是WSL(1),因此我们要更新一下
打开cmd,输入wsl --update,回车运行,等待进度条完成后重启电脑
下载
前往Docker官网:
鼠标移动到官网的“Download Docker Desktop”按钮上,再点击“Download for Windows - AMD64”选项下载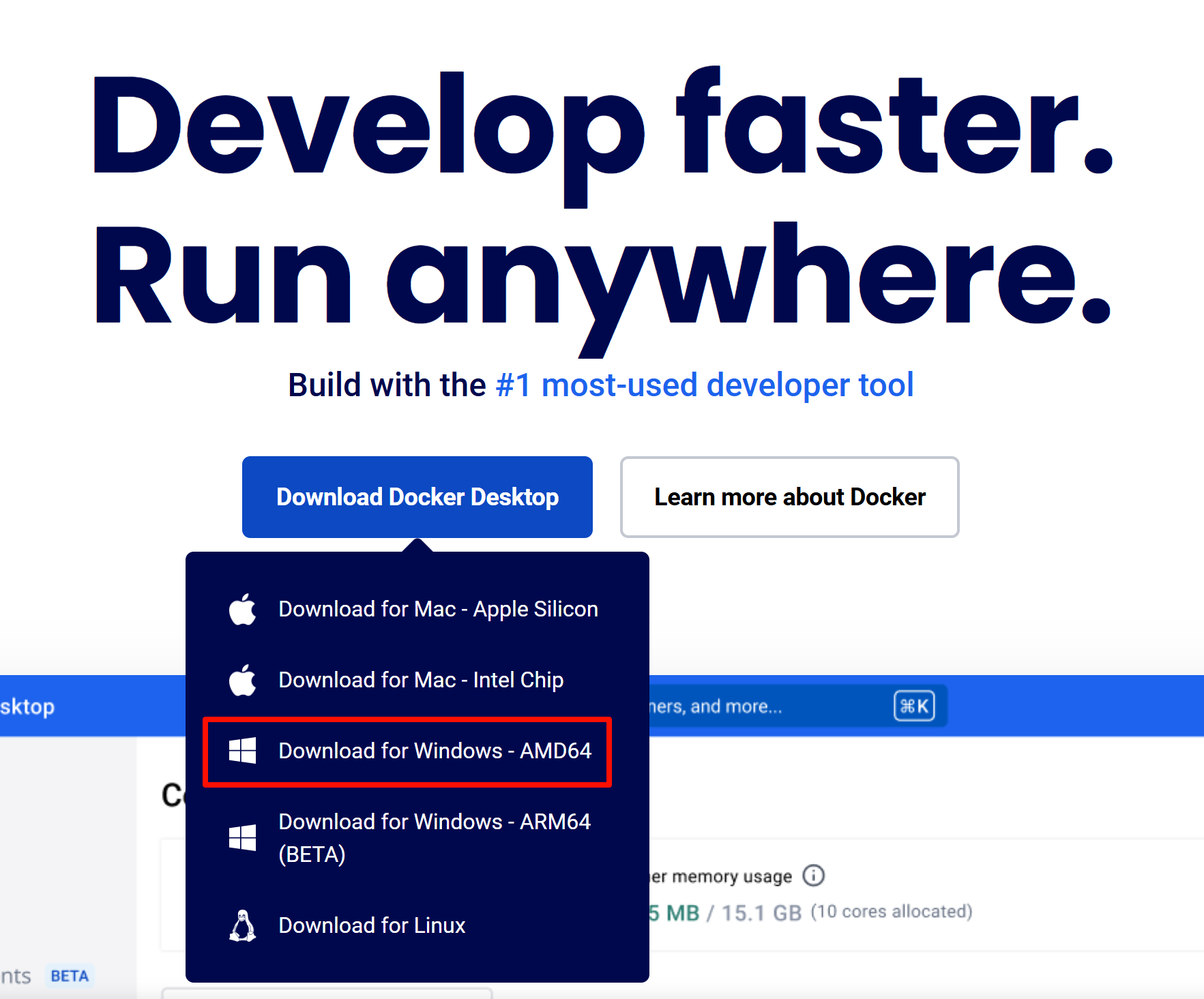
安装
运行刚刚下载的Docker Desktop Installer.exe,点击“OK”,等待安装程序运行完成|
Docker默认安装在C盘且不可更改路径,需占用磁盘约3GB空间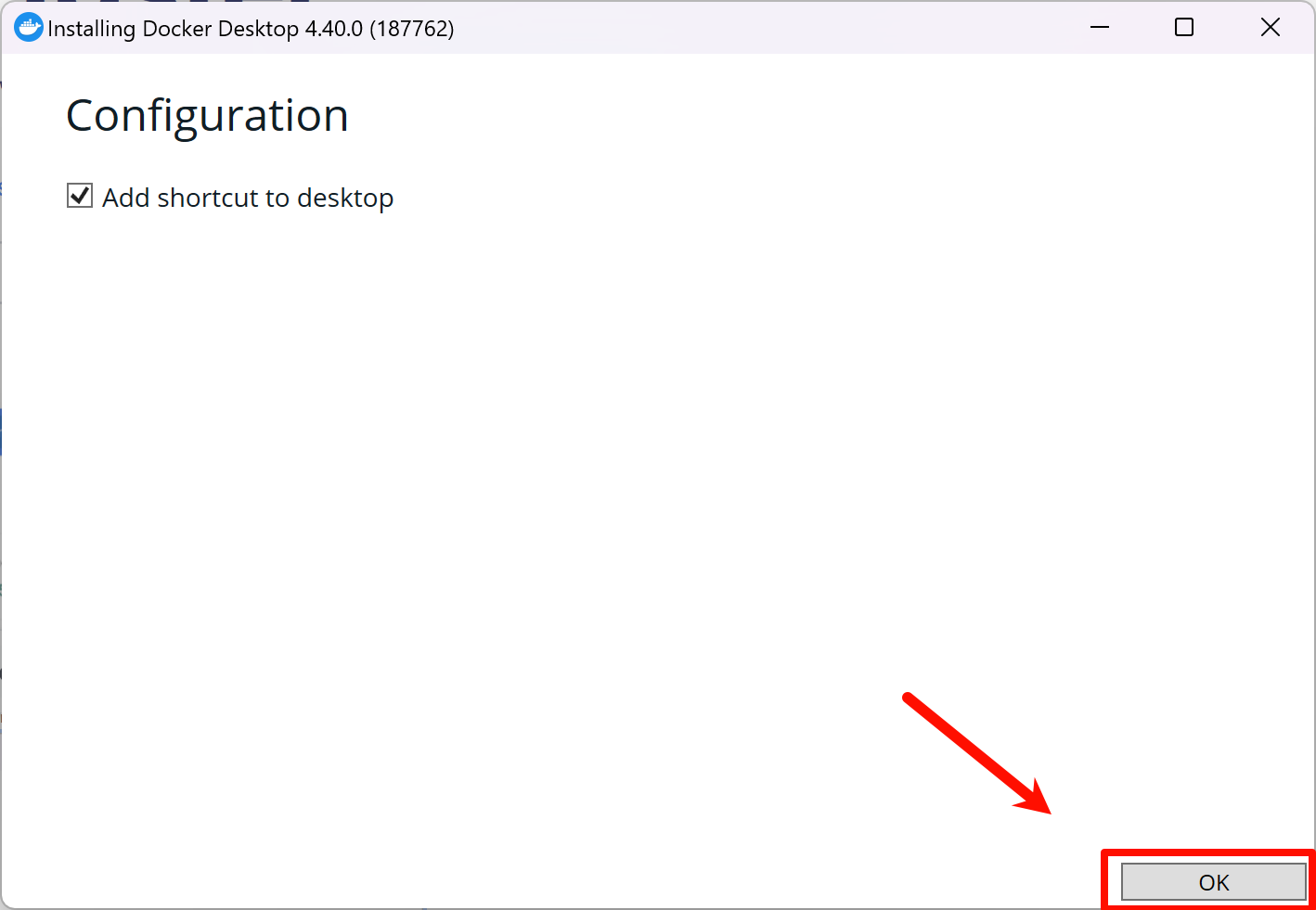
安装完成后需要点击界面中间的蓝色按钮
这一步会重启电脑,所以请先保存你的文件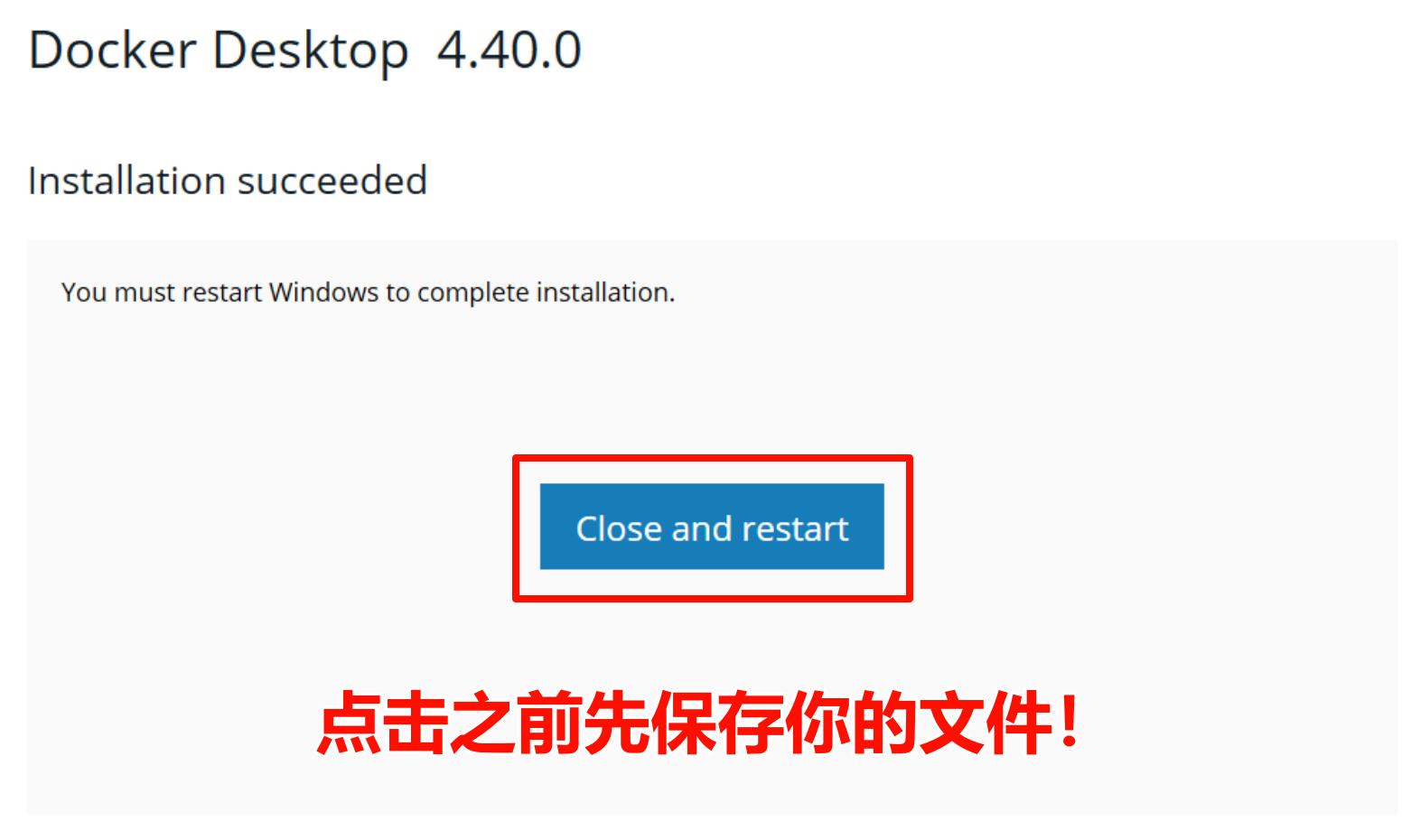
配置
重新进入桌面,Docker会自动运行并弹出一个窗口,要求你同意服务协议,点击Accept即可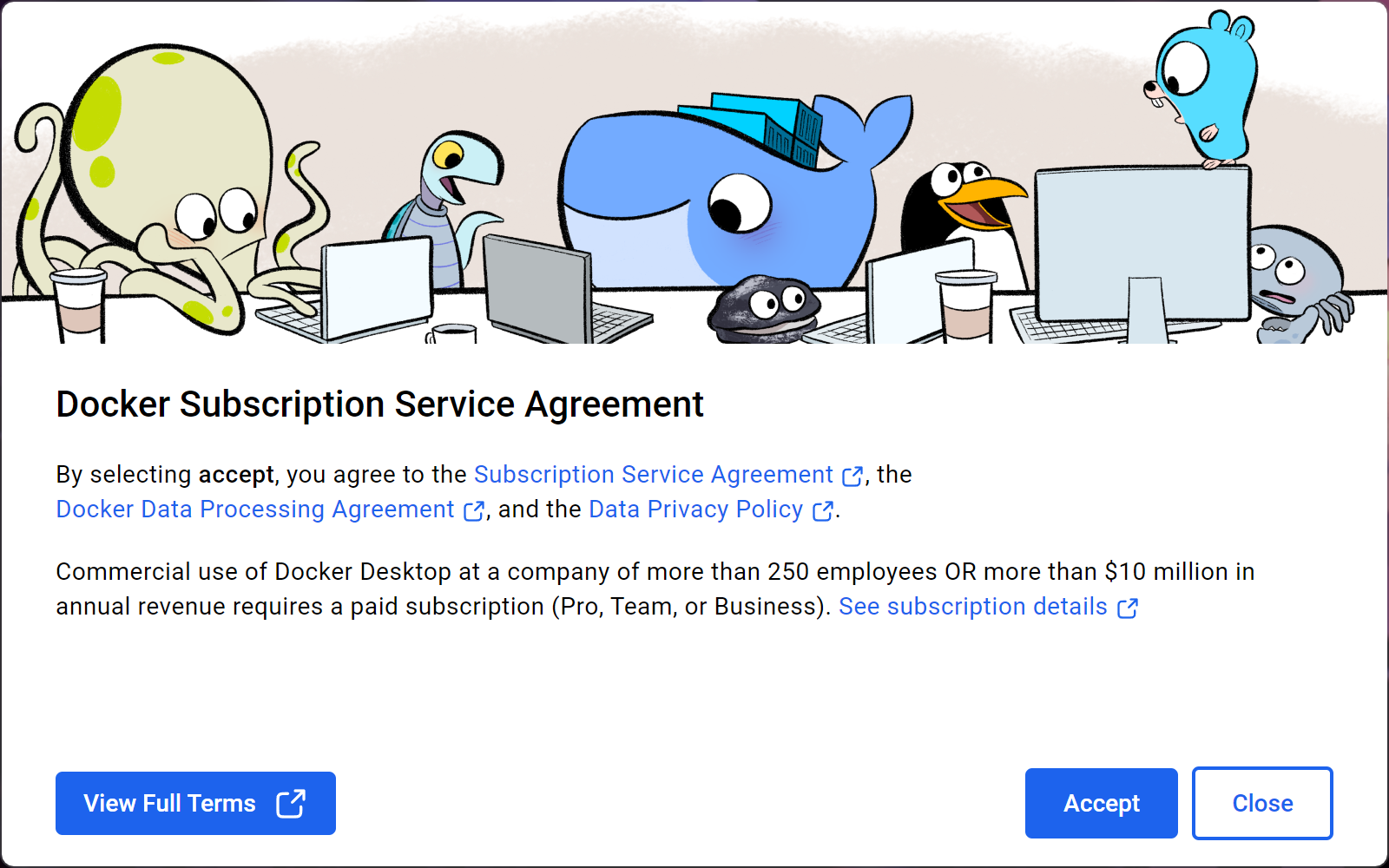
随后会弹出另一个界面,问你使用推荐设置还是自定义设置,我们选第一个推荐设置,点击Finish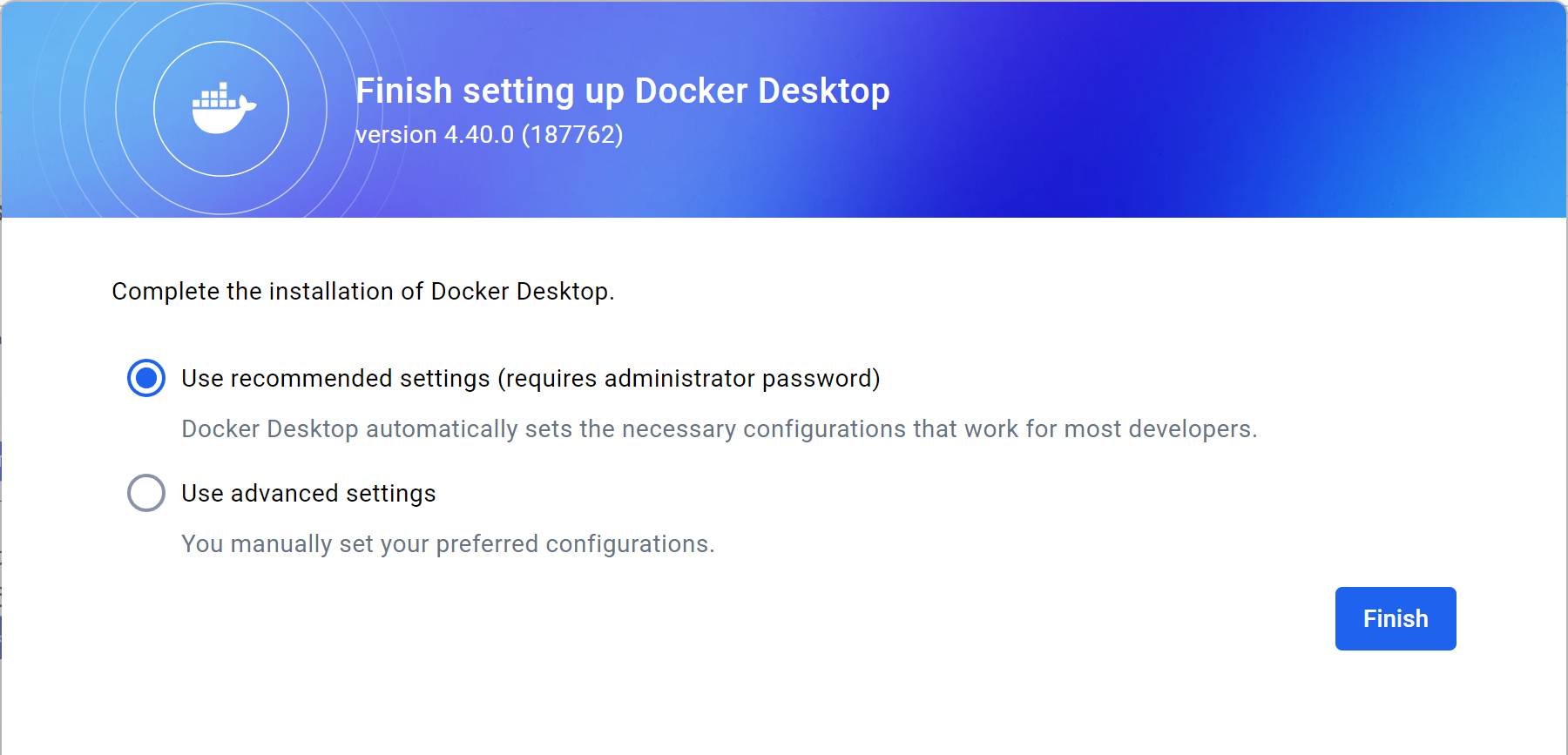
再之后会弹出Docker主界面,如果你需要的话可以登录账户,Work是工作账户,Personal是个人账户
也可以点击右上方的Skip按钮直接跳过登录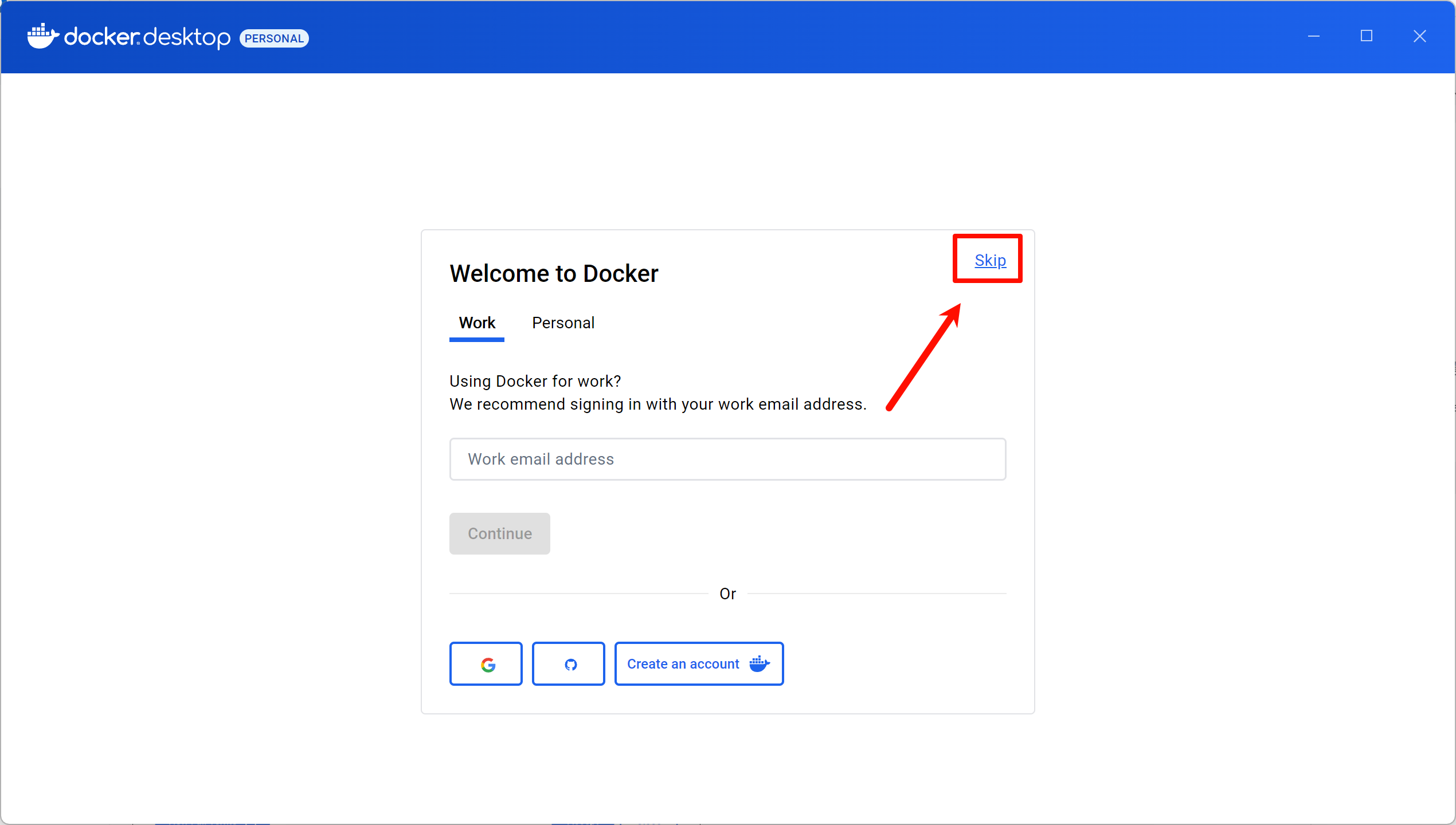
之后会问你工作类型什么的,同样点击右上方的Skip按钮直接跳过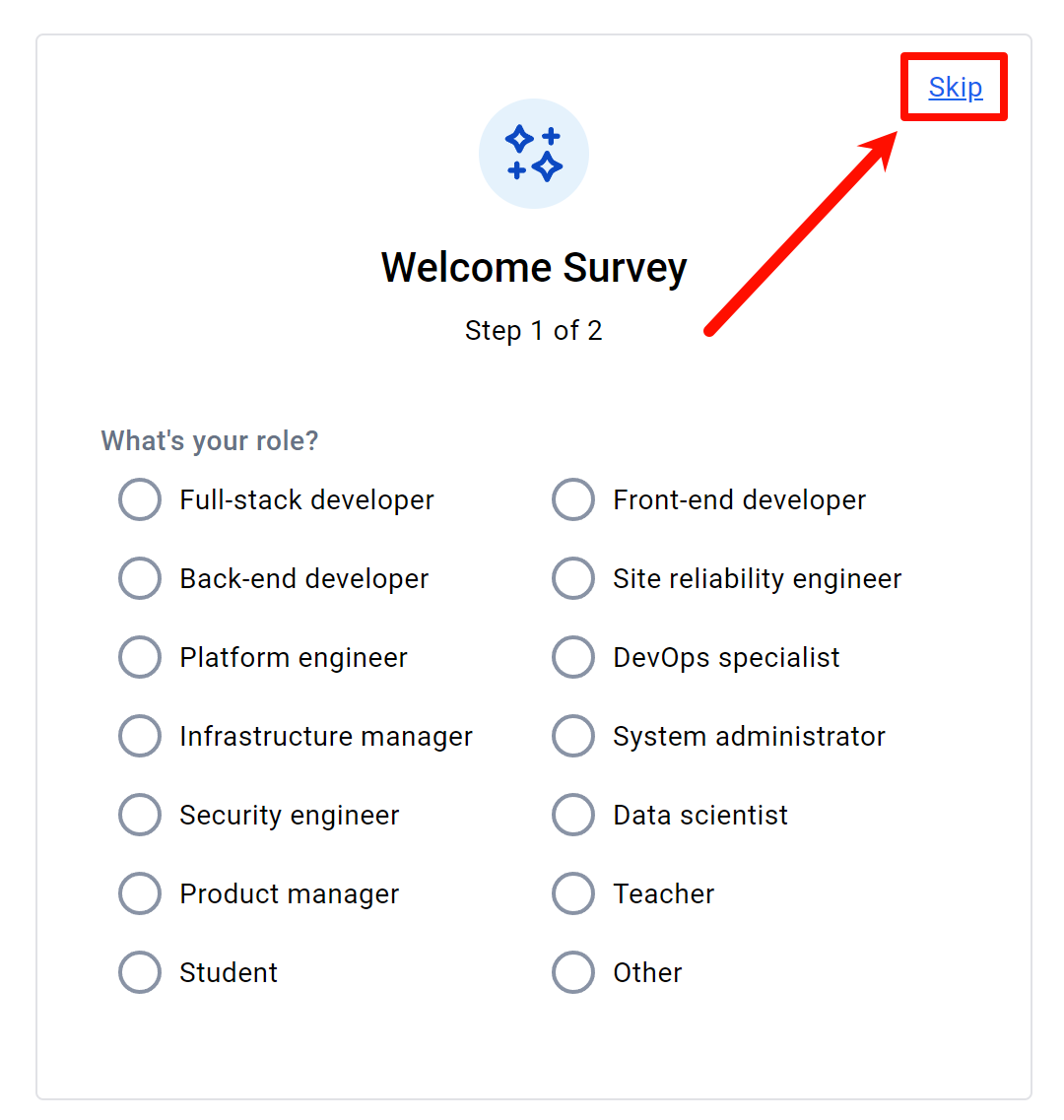
之后会进入主页,Docker就配置完成了
如果你的界面上显示“Engine Stopped”,说明WSL虚拟机还未安装完成,耐心等待
初次安装WSL会弹出WSL入门页面,直接关闭即可
设置镜像源(可选)
由于众所周知的原因,国内很难访问国外网站,因此使用Docker官方源下载要非常久,阿里云等大厂镜像源也因特殊原因关停,因此只能使用民间自建的镜像源
民间自建镜像源存在时效性,作者不保证此处的镜像源依旧可用,仅供参考
打开Docker主界面,点击右上角的Settings按钮,再进入Docker Engines选项,这里会显示一个文本框,显示Docker配置文件的内容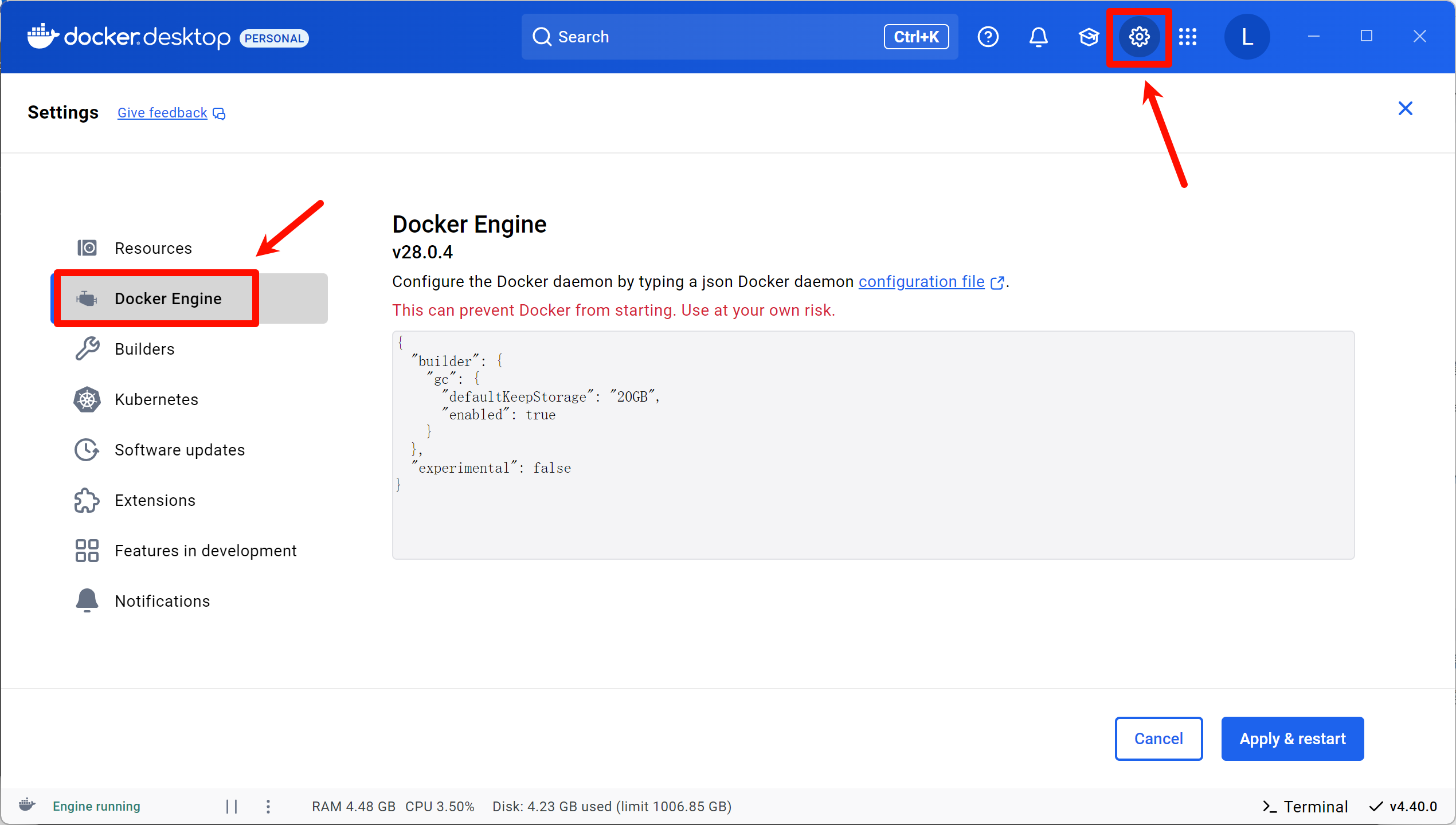
我们需要在倒数第二行的末尾添加一个半角逗号(英文逗号)“,”,换行,粘贴以下代码:
"registry-mirrors": [
"https://docker.hpcloud.cloud",
"https://docker.m.daocloud.io",
"https://docker.unsee.tech",
"https://docker.1panel.live",
"http://mirrors.ustc.edu.cn",
"https://docker.chenby.cn",
"http://mirror.azure.cn",
"https://dockerpull.org",
"https://dockerhub.icu",
"https://hub.rat.dev"
]拼接后的完整配置文件内容如下: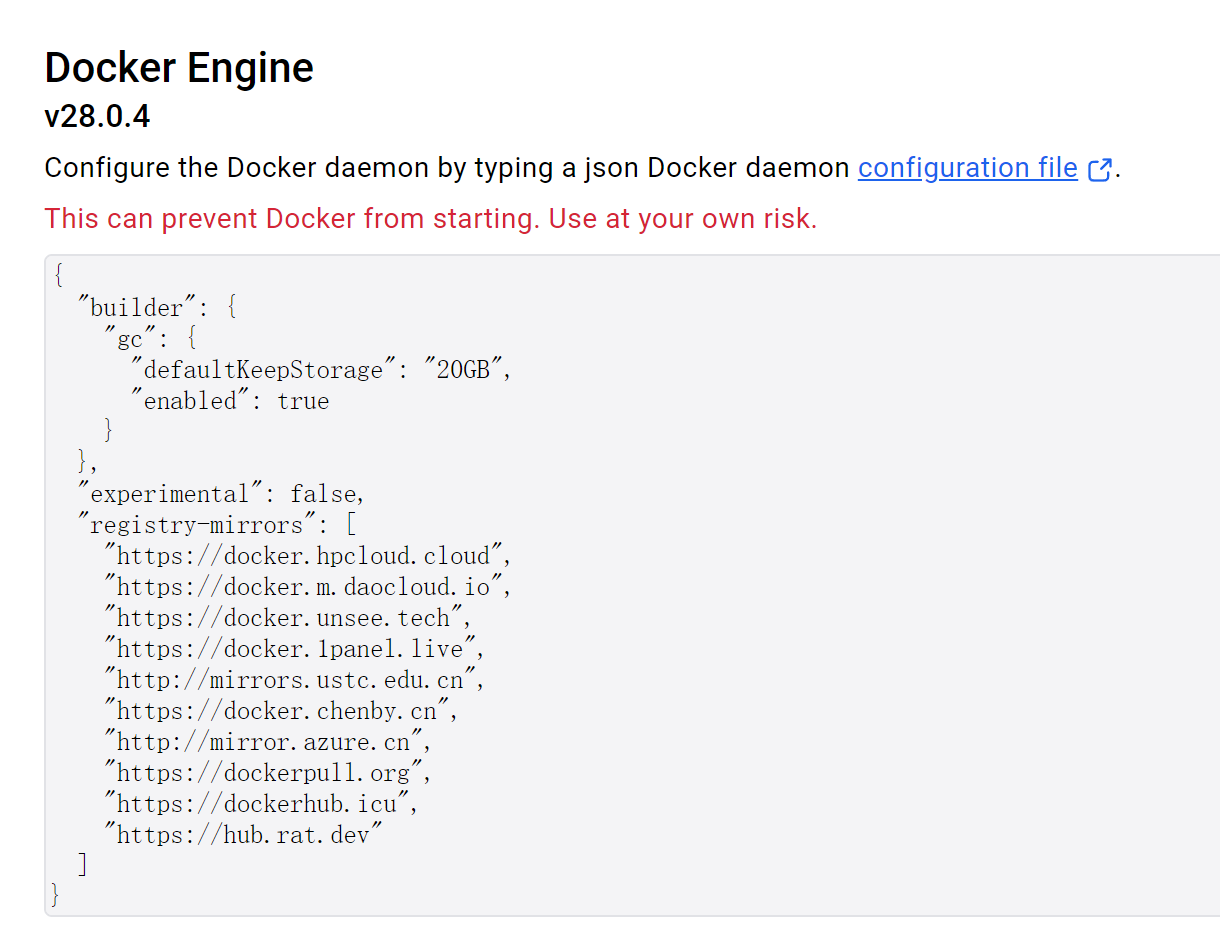
修改完成后点击右下角的“Apply & restart”按钮,会重启Docker,镜像源就设置完成了
在Docker中部署RAGFlow
RAGFlow是一个RAG(检索增强生成)引擎,利用它可以创建本地知识库,教会大模型新内容
下载
前往RAGFlow的仓库页面:
点击右上角的“代码”按钮,再点击“下载压缩包”,下载最新版本的文件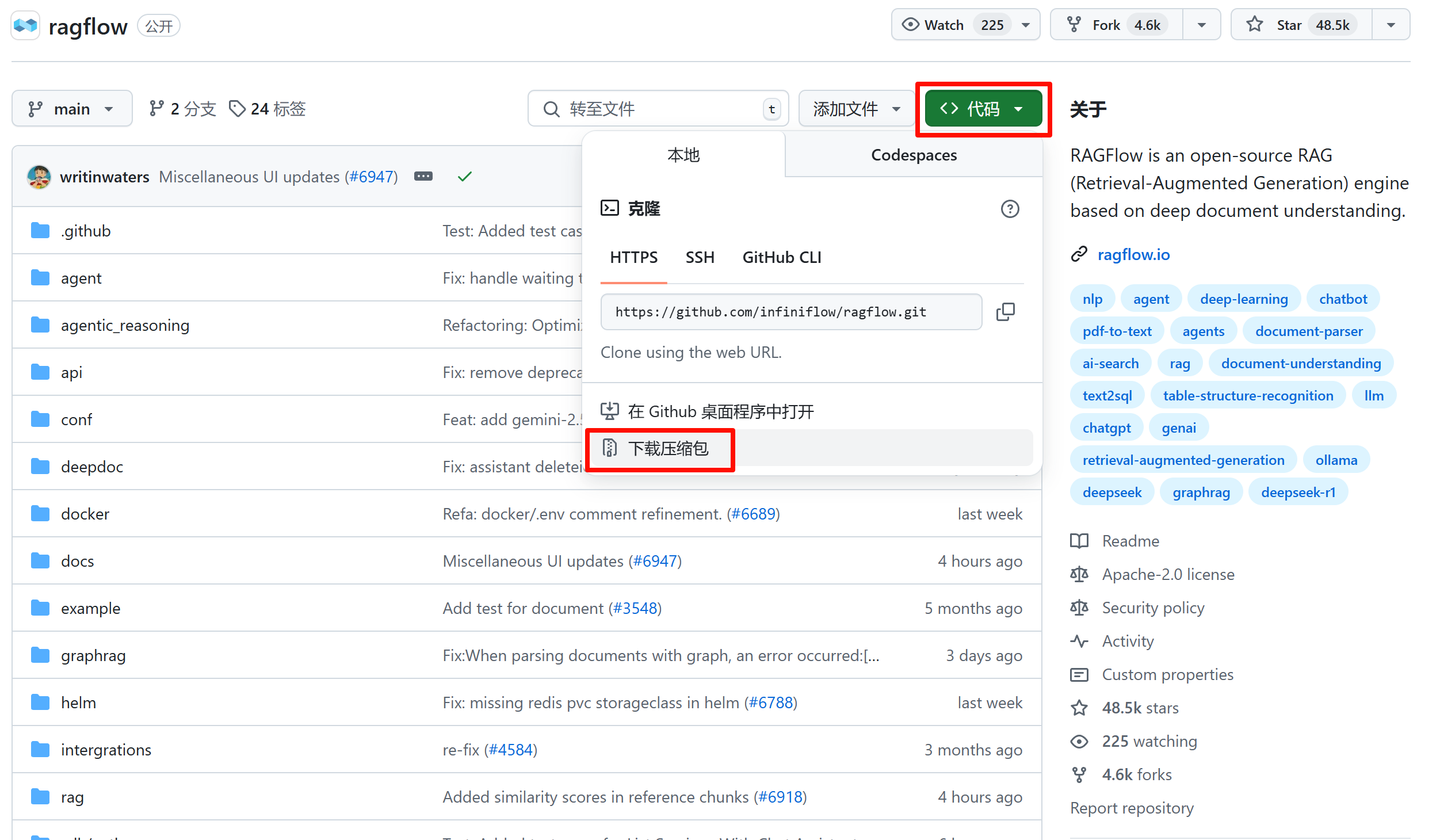
修改
查阅仓库中的说明文件,提到了直接使用Docker部署的是v0.17.2-slim版本
而这个版本是不包含embedding模型的,因此我们需要修改一下文件
将下载好的压缩包解压到电脑,进入源代码中的docker目录
找到其中的.env文件,使用记事本或其他文本编辑器打开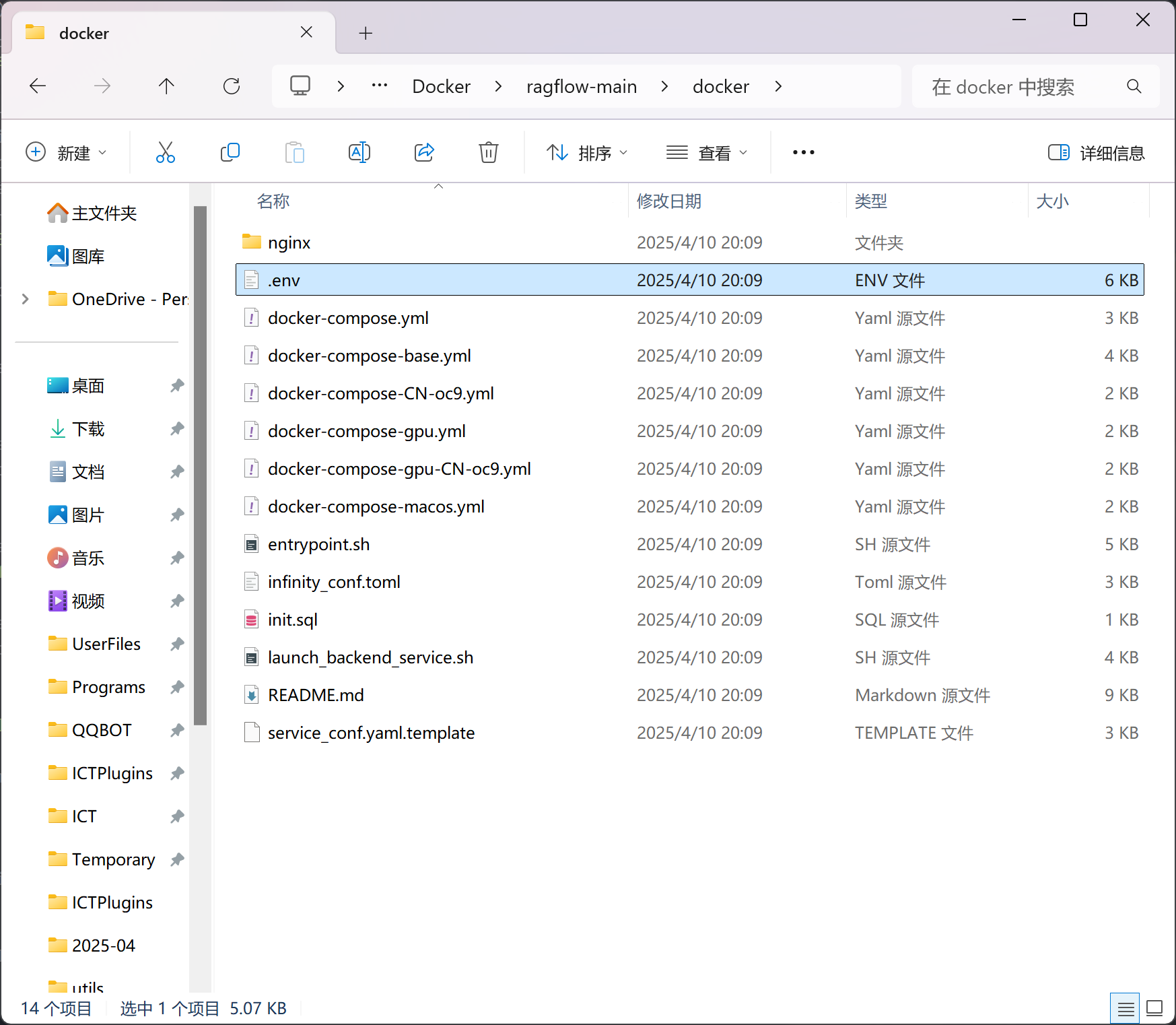
按下Ctrl+F启用查找功能,找到写着RAGFLOW_IMAGE的这几行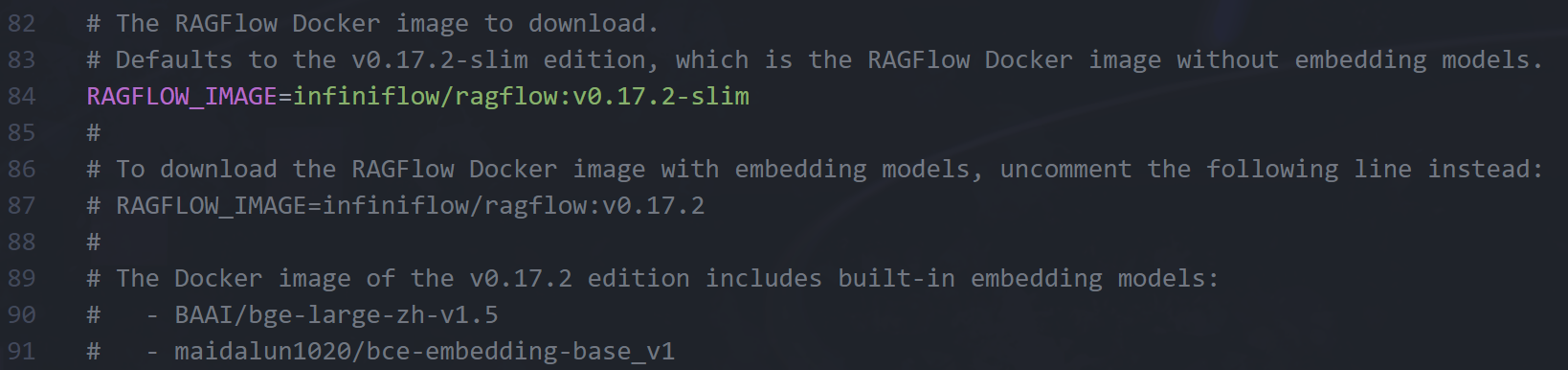
我们只需要在第84行前面添加一个#,再把第87行前面的#删掉,保存修改过后的.env文件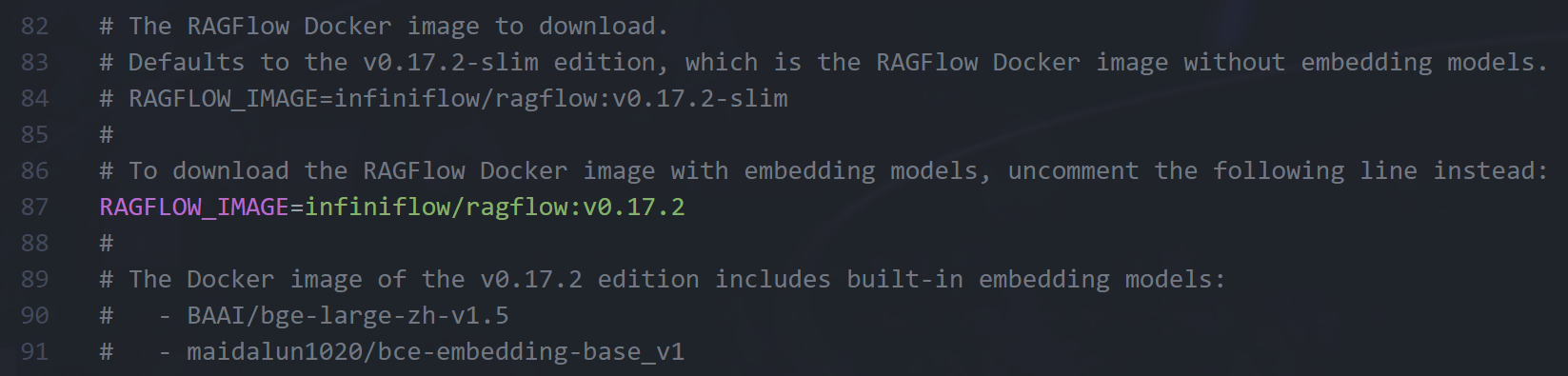
部署
在刚刚的文件夹空白处右键,选择“在终端中打开”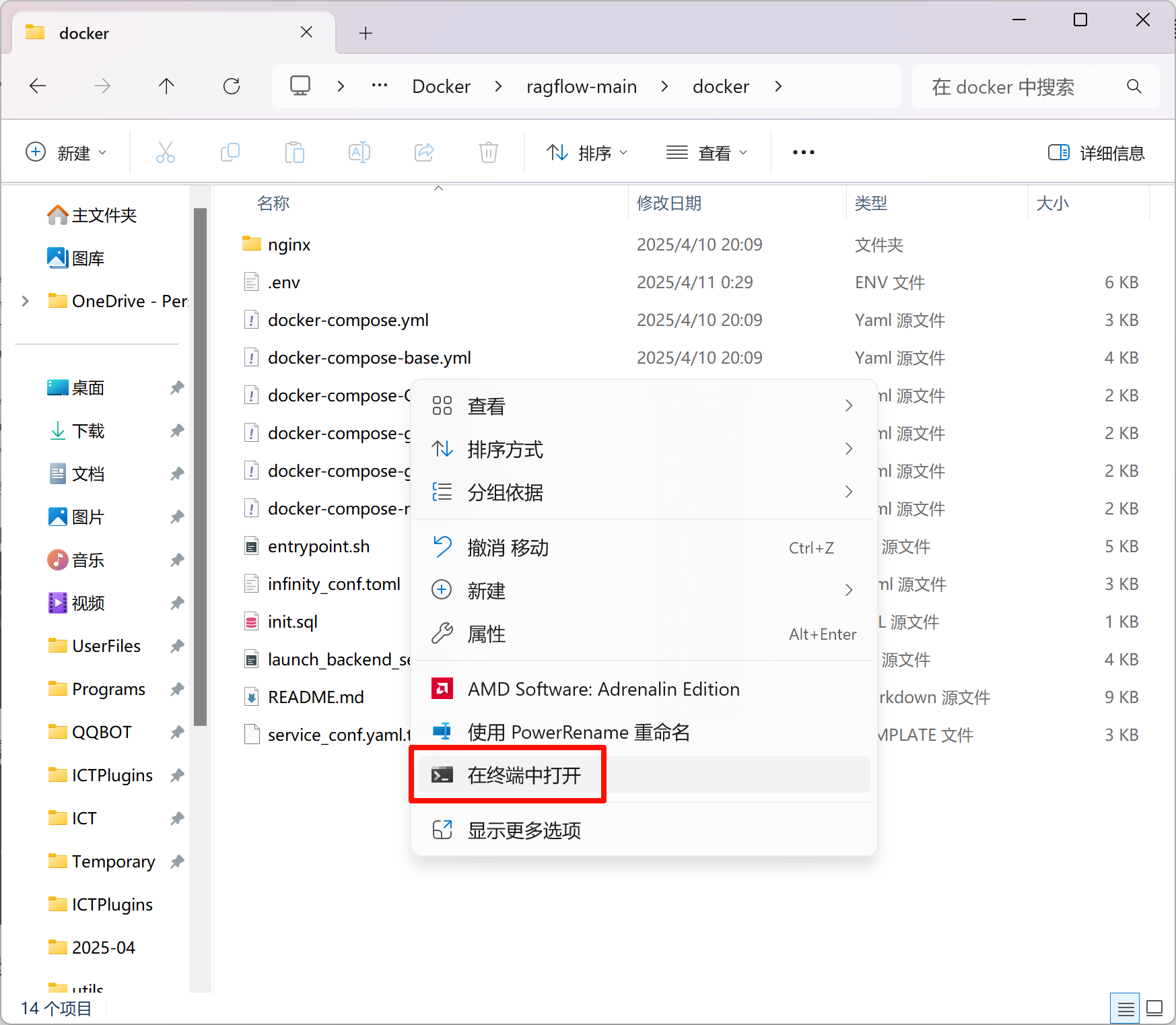
输入命令 docker compose -f docker-compose.yml up -d ,按回车运行,Docker会开始部署RAGFlow
会被部署到Docker虚拟机的位置,部署时间较长,需占用磁盘约12GB空间
如果进度卡住很久不动,可以Ctrl+C强制结束再重新执行命令,Docker有断点续传功能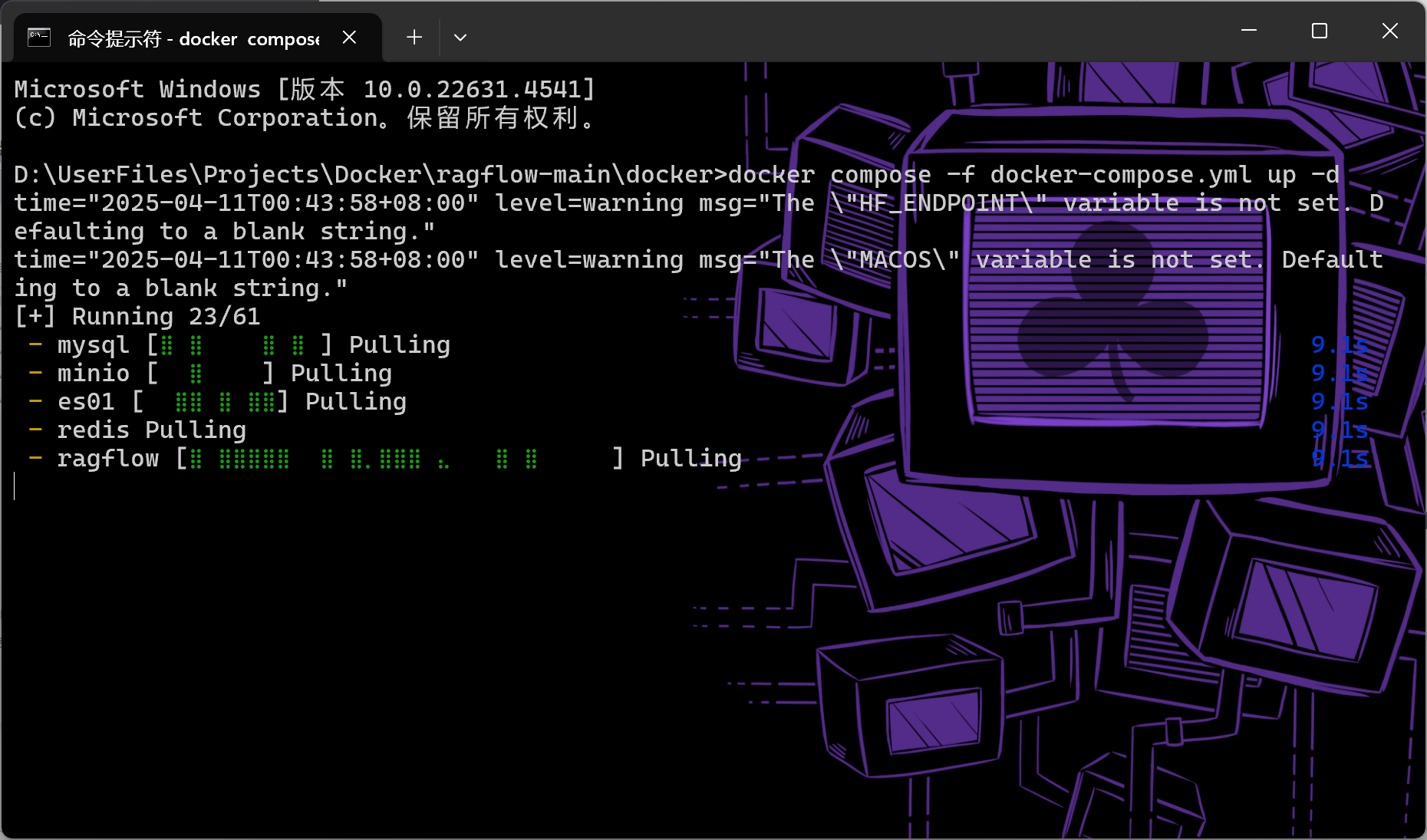
部署完成后会弹出防火墙提醒,同样点击允许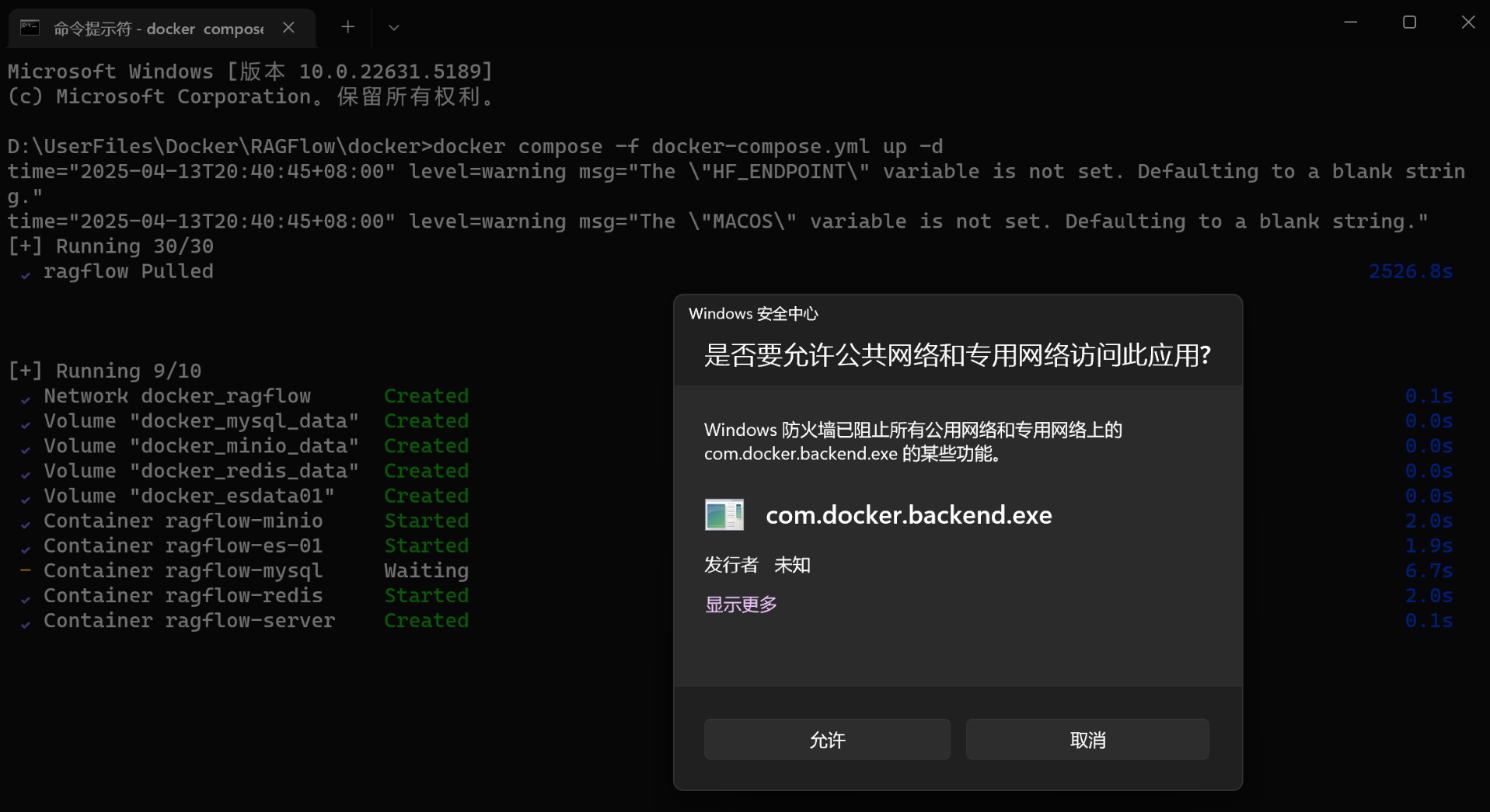
配置
打开RAGFlow
如果你没有修改过文件,RAGFlow默认监听80端口,在浏览器地址栏输入localhost即可进入RAGFlow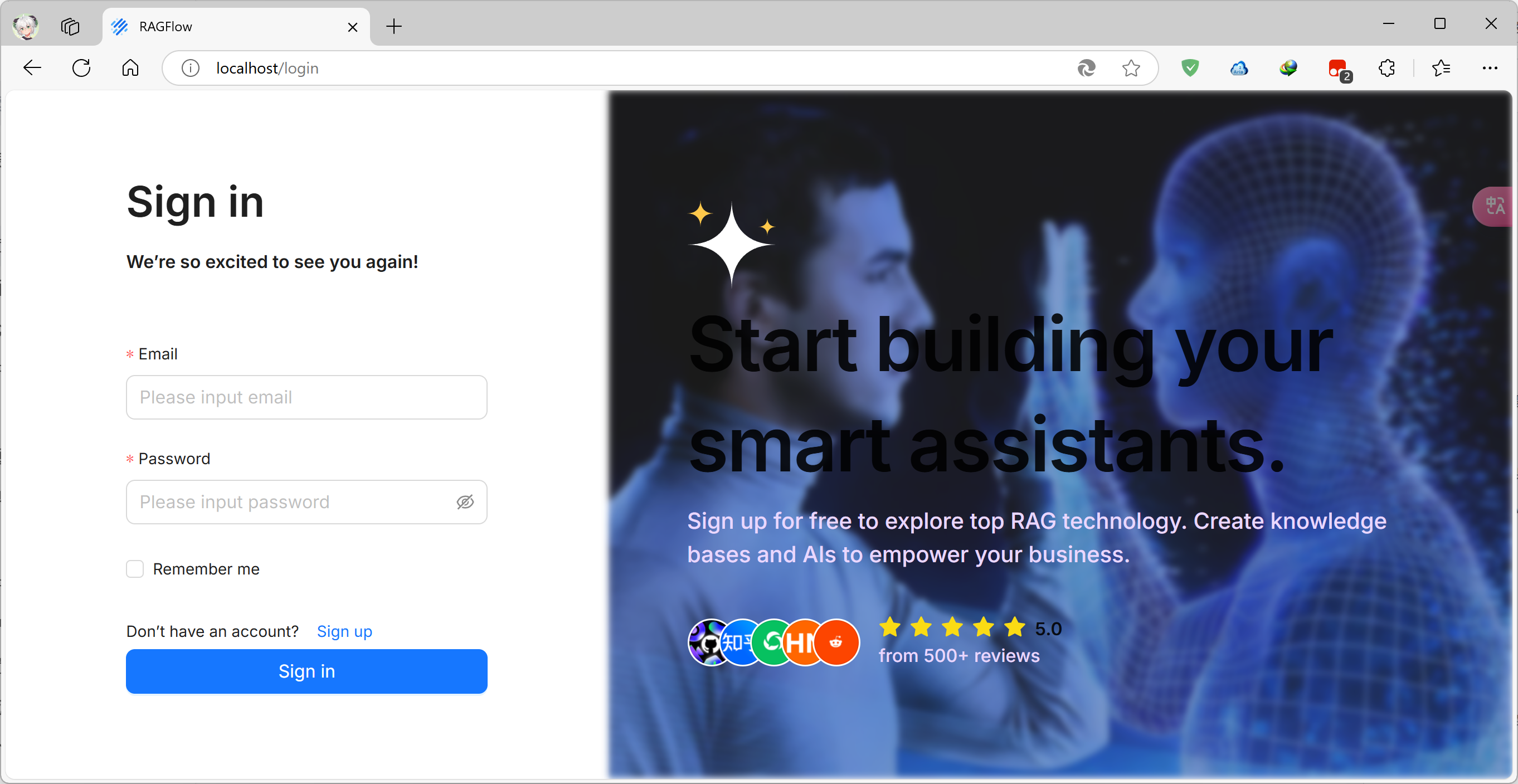
注册新账号并登录
因为我们刚刚才部署好RAGFlow,此时后台还没有任何账户,我们需要点击Sign up来创建一个账户
依次填入邮箱地址、名称、密码即可注册
点击Continue按钮后会回到登录界面,这里已经自动填写了刚刚注册时的邮箱和密码
勾选“Remember me”则会记住登录信息,下次进入就不需要重新登陆了,然后点击“Sign in”按钮登录
设置页面语言
登录成功后在主页右上角有语言选项,选择简体中文后RAGFlow就会使用中文界面
在RAGFlow添加ollama的模型
先点击主页右上角的头像进入设置,再进入模型提供商选项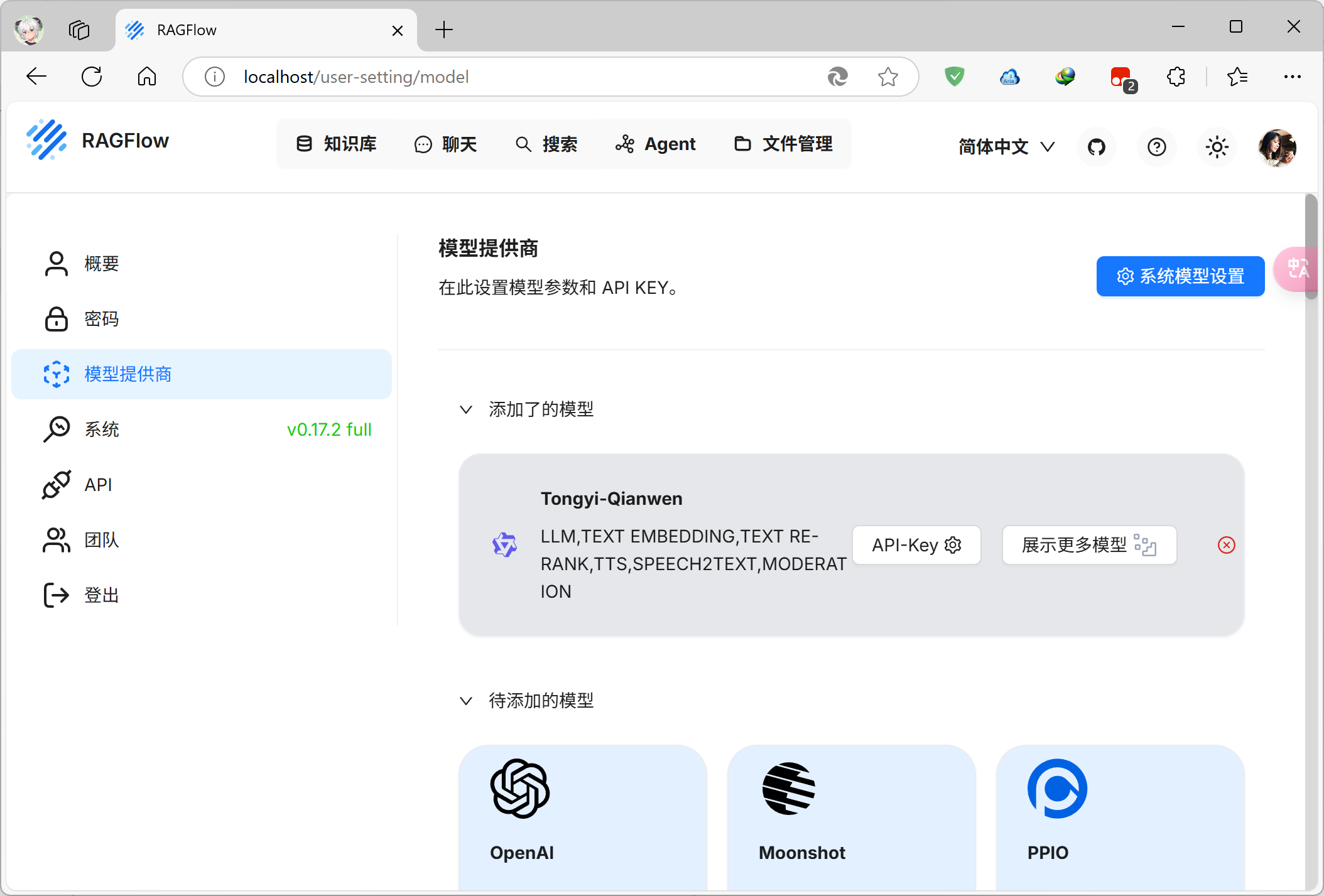
这里会显示有一个添加了的同义千问模型,实际上是用不了的,只是个预设配置,点右边的红色小X给他删除
然后往下滑找到ollama,点击这里的添加模型
我们之前部署的是deepseek-r1 1.5b模型,这是个chat(对话)模型,因此模型类型需要选择chat
模型名称可以通过在cmd执行ollama list命令查看
基础Url也就是部署了ollama的电脑的IP地址,这里不能填写localhost,因为RAGFlow正运行在虚拟机中
格式为http://<IP地址>:<端口号>
API-Key不填写,因为我们通过ollama本地部署模型,没有API-Key
最大Token数随意,但不推荐小于1000,否则模型输出可能被截断
所有信息核对无误后点击确定按钮,我们部署的这个模型就被添加到RAGFlow中了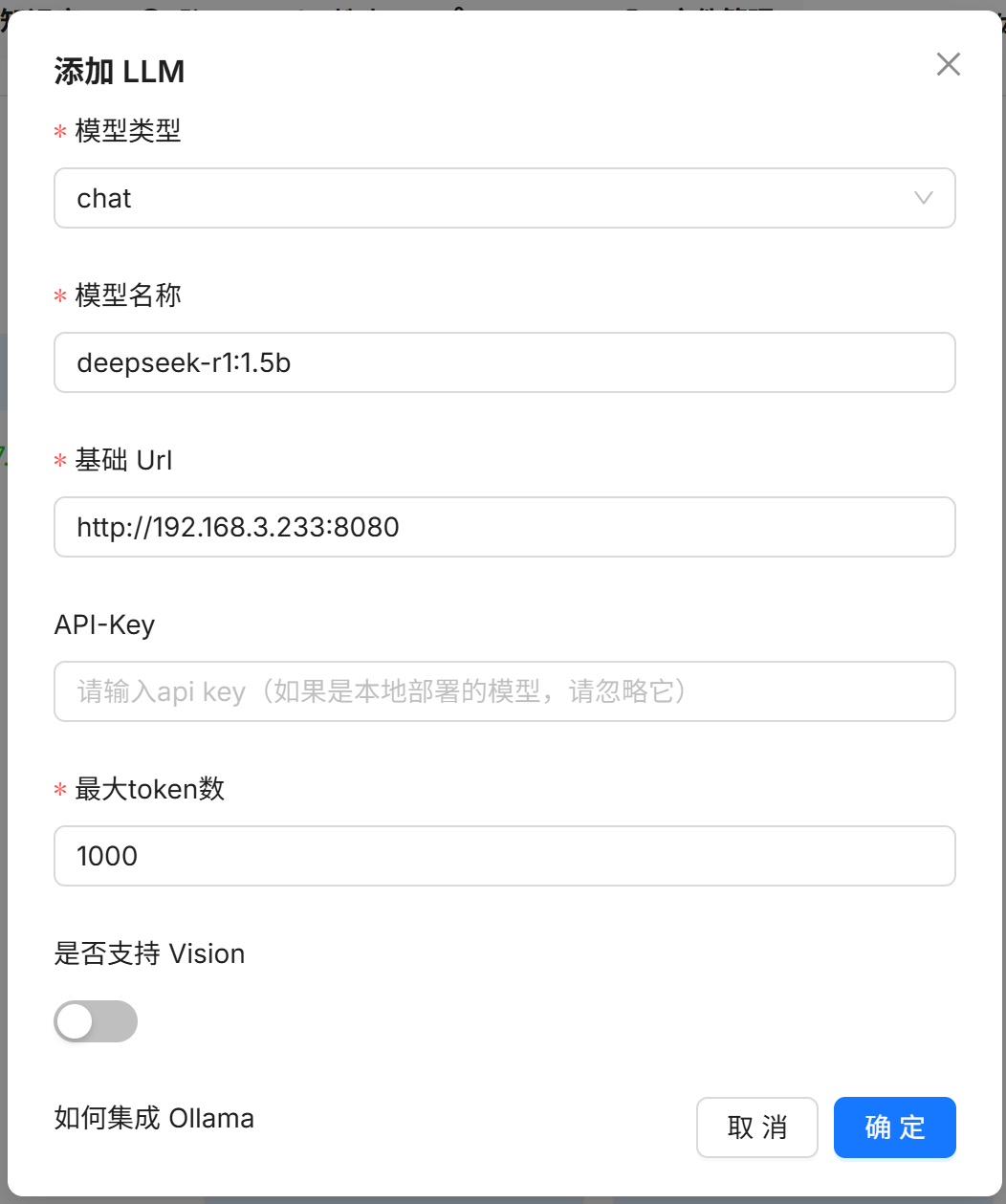
然后点击右上角的系统模型设置,聊天模型中选择刚刚添加的ollama,这样RAGFlow就会在对话时调用ollama了
最开始我们部署的是包含embedding模型的RAGFlow,因此嵌入模型这里已经自动选择了一个模型,保持不变,点击确定即可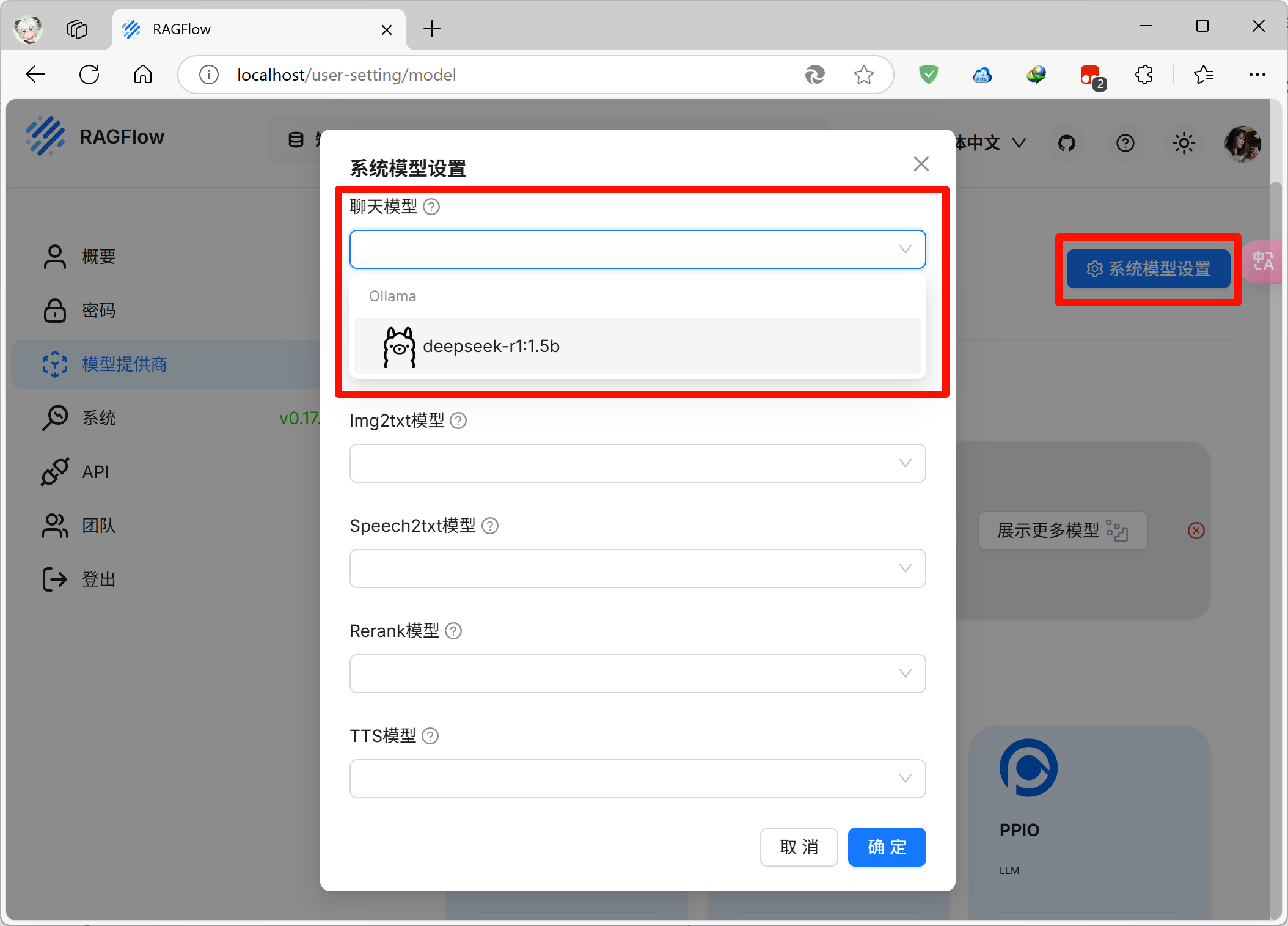
创建知识库
知识库相当于大模型的“海马体”,跟字面意思一样,是存储知识的地方,我们把要教给模型的东西放入知识库中
点击页面上方切换到知识库页面,点击右上角的创建知识库,名称自拟,过于随意或无意义的命名可能会影响模型判断
我以我喜欢的一款游戏《东方夜雀食堂》作为例子,这是一款模拟经营游戏,我将在知识库中添加这款游戏所有菜品的信息,让模型能够根据客人的喜好Tag和预算来给出推荐菜品
输入知识库名字“夜雀食堂菜品大全”,进入更详细的配置页面
描述信息可填可不填,不重要
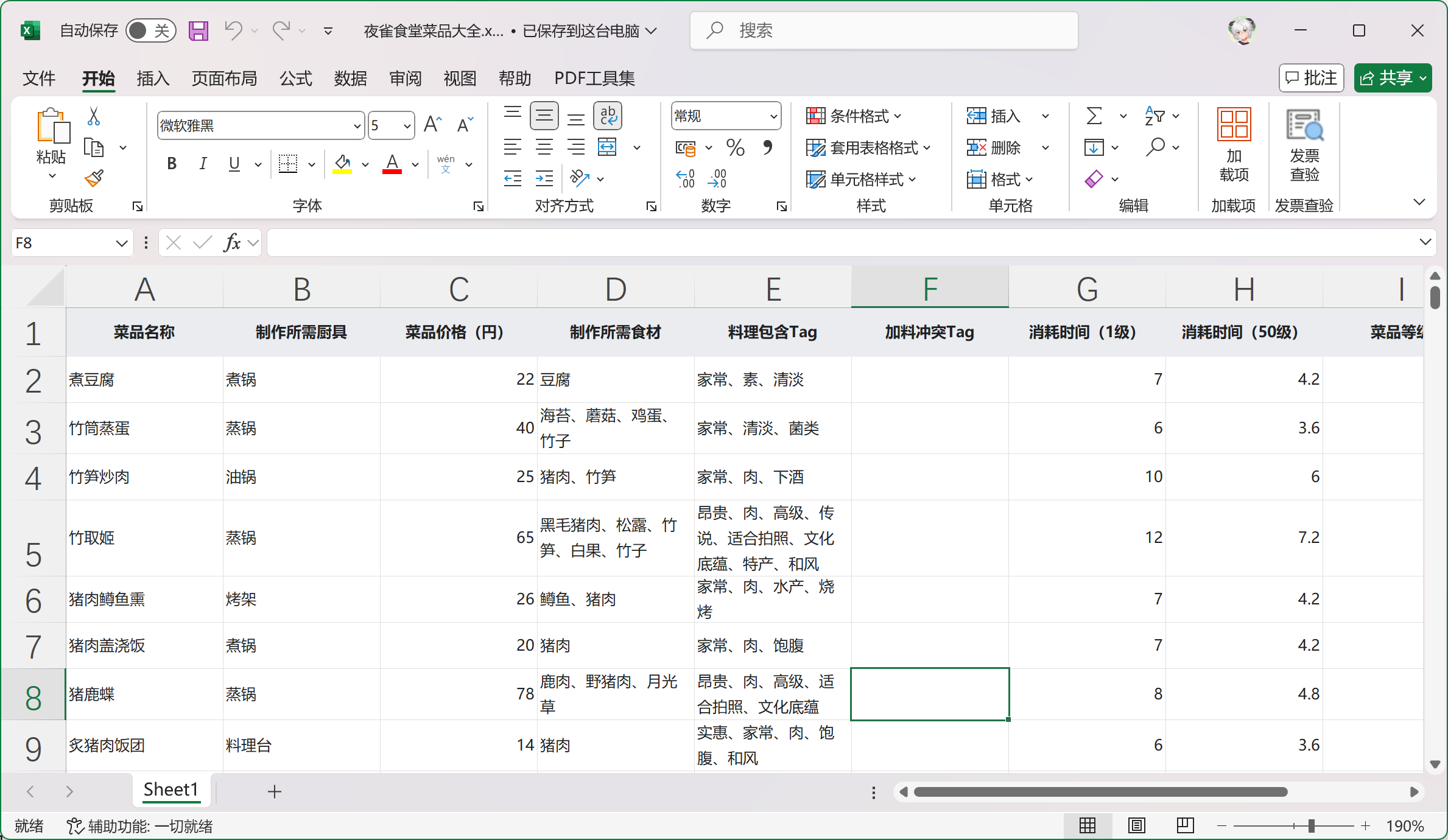
因为我的菜品信息存储在表格中,因此切片方法选择Table效果更好,无需求的话保持默认的General即可
其他参数一般保持默认,点击下方的保存按钮即可成功创建知识库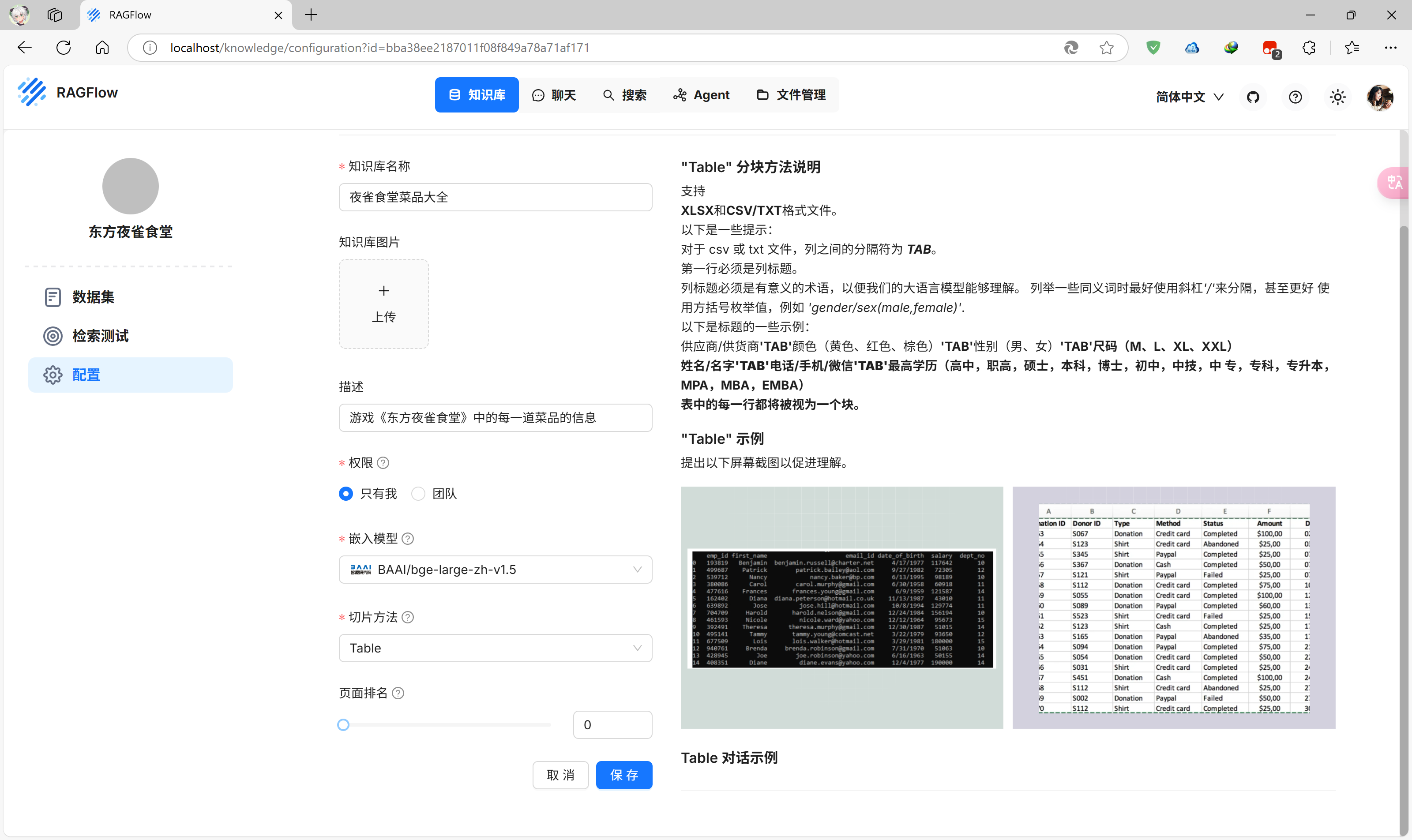
之后会进入知识库的页面,点击右侧的新增文件,再点击本地文件,即可上传需要放进知识库里的文件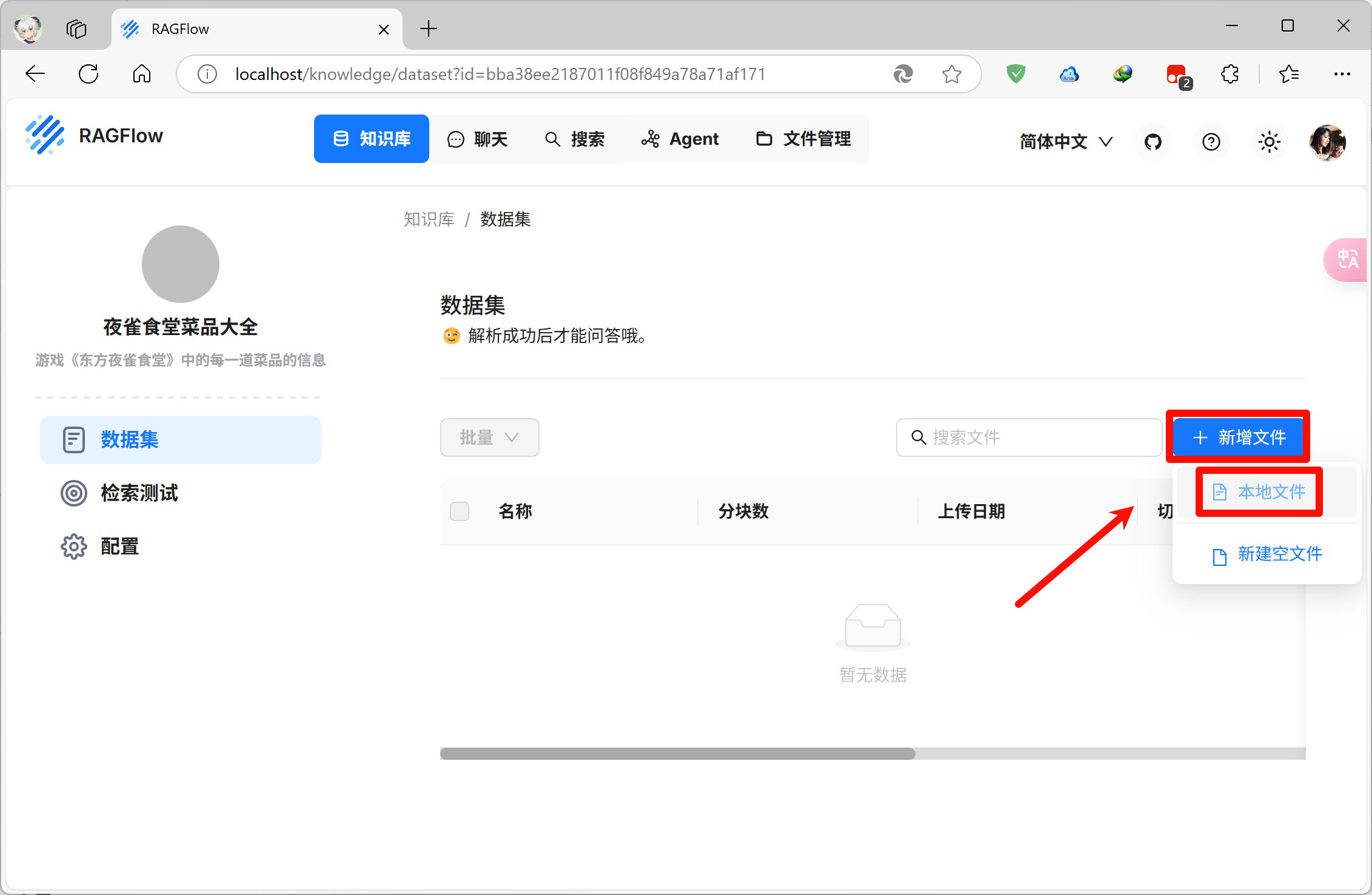
如果你没有选择“创建时解析”,那么文件是不会被解析的,需要手动点击按钮开始解析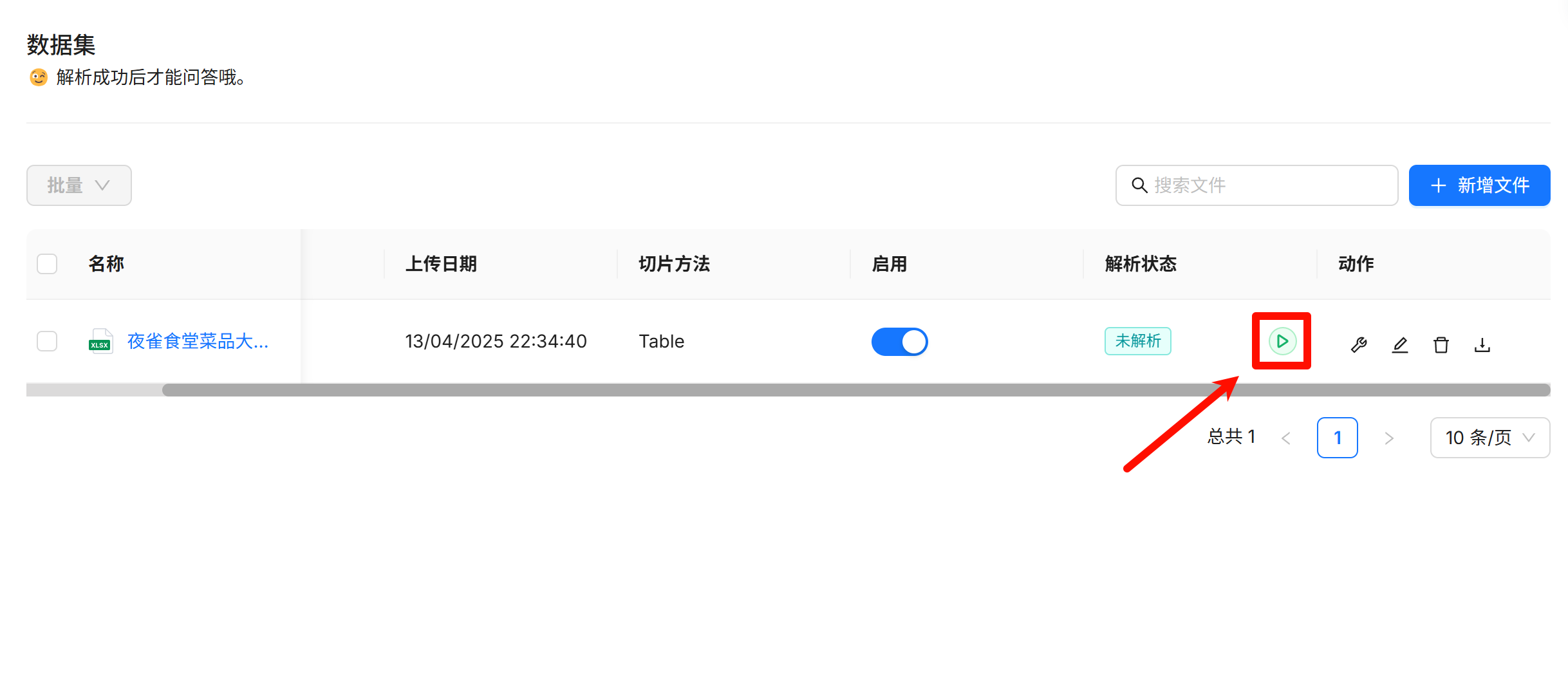
解析时长和文件的内容量有关,静静等待解析完成即可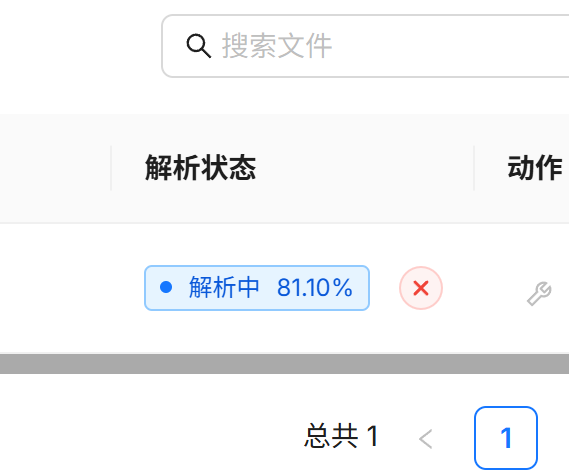
解析状态变为“成功”即代表文件解析完成,知识库也创建完成了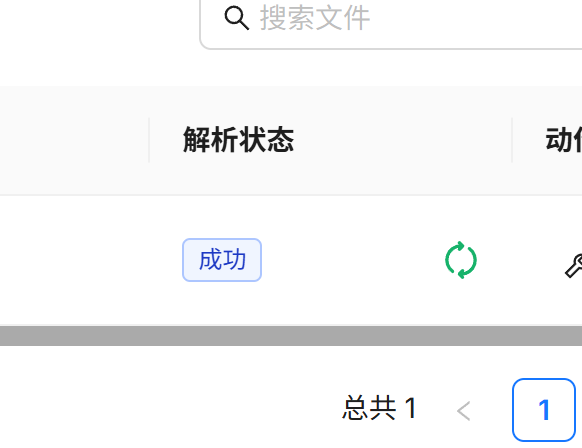
创建助理
"助理"也就是大模型的“人设”,我们需要给模型一个人设,才能更好的结合知识库生成内容
点击页面上方切换到聊天页面,点击左上角的新建助理进入聊天配置
聊天配置共分为三个板块:助理设置、提示引擎、模型设置,我们一个个来
助理设置
这里是助理的一些基本设置
助理姓名也就是模型自己的名字,既然现在在围绕游戏来做,我直接以游戏中的角色“幽谷响子”命名了
助理描述可填可不填,不重要
开场白是每次对话时模型对用户说的第一句话,自拟
最重要的是最下方的知识库,需要添加创建好的知识库,不然模型获取不到这些知识的
其他设置保持默认即可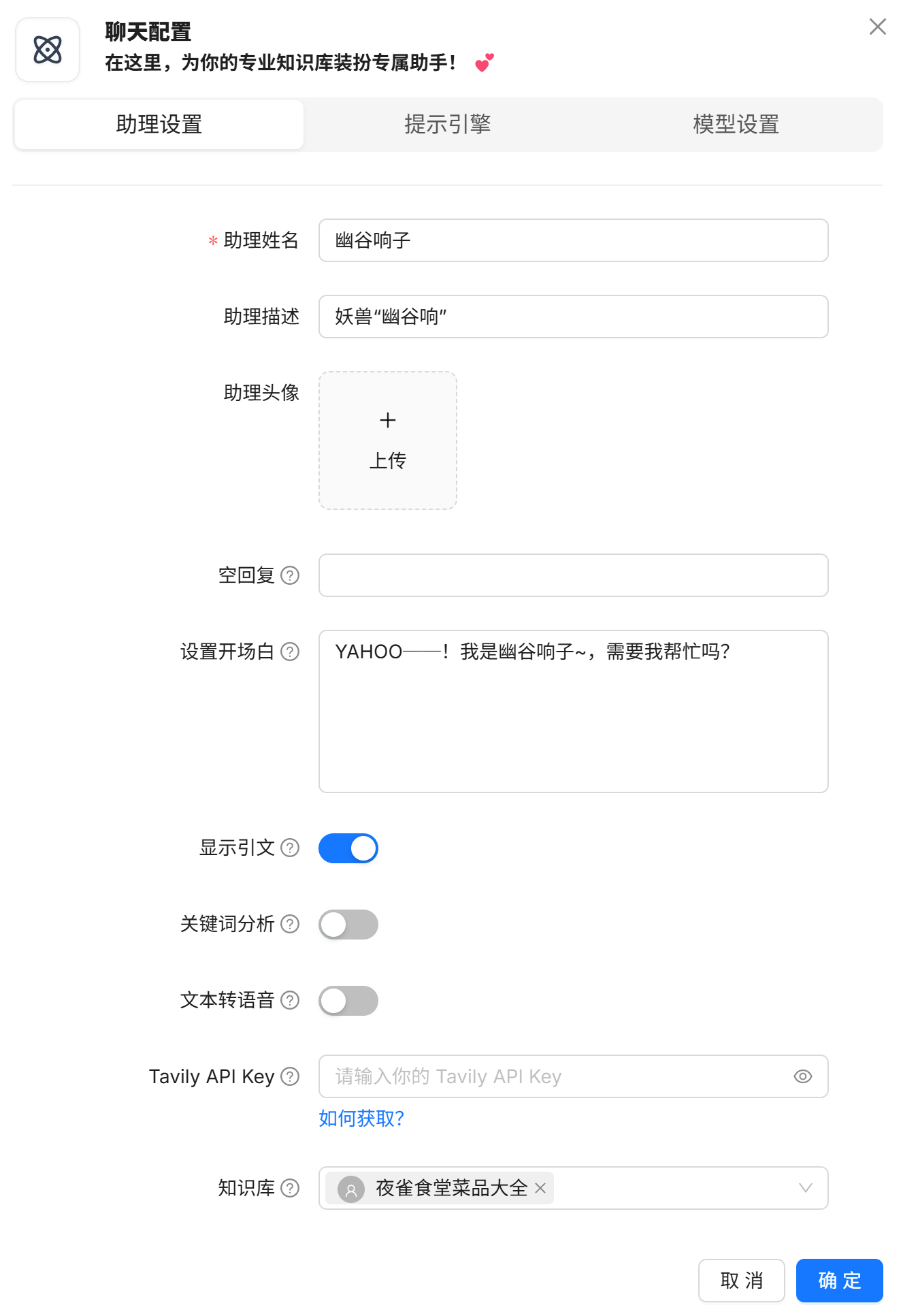
提示引擎
这里是模型关于提示词的一些设定
系统提示词就是在会话开始前系统交给大模型的“人设”,这里需要以第三人称描述模型的种种设定,比如在特定情况下需要如何回答等等
其他设置比较深奥,一般保持默认即可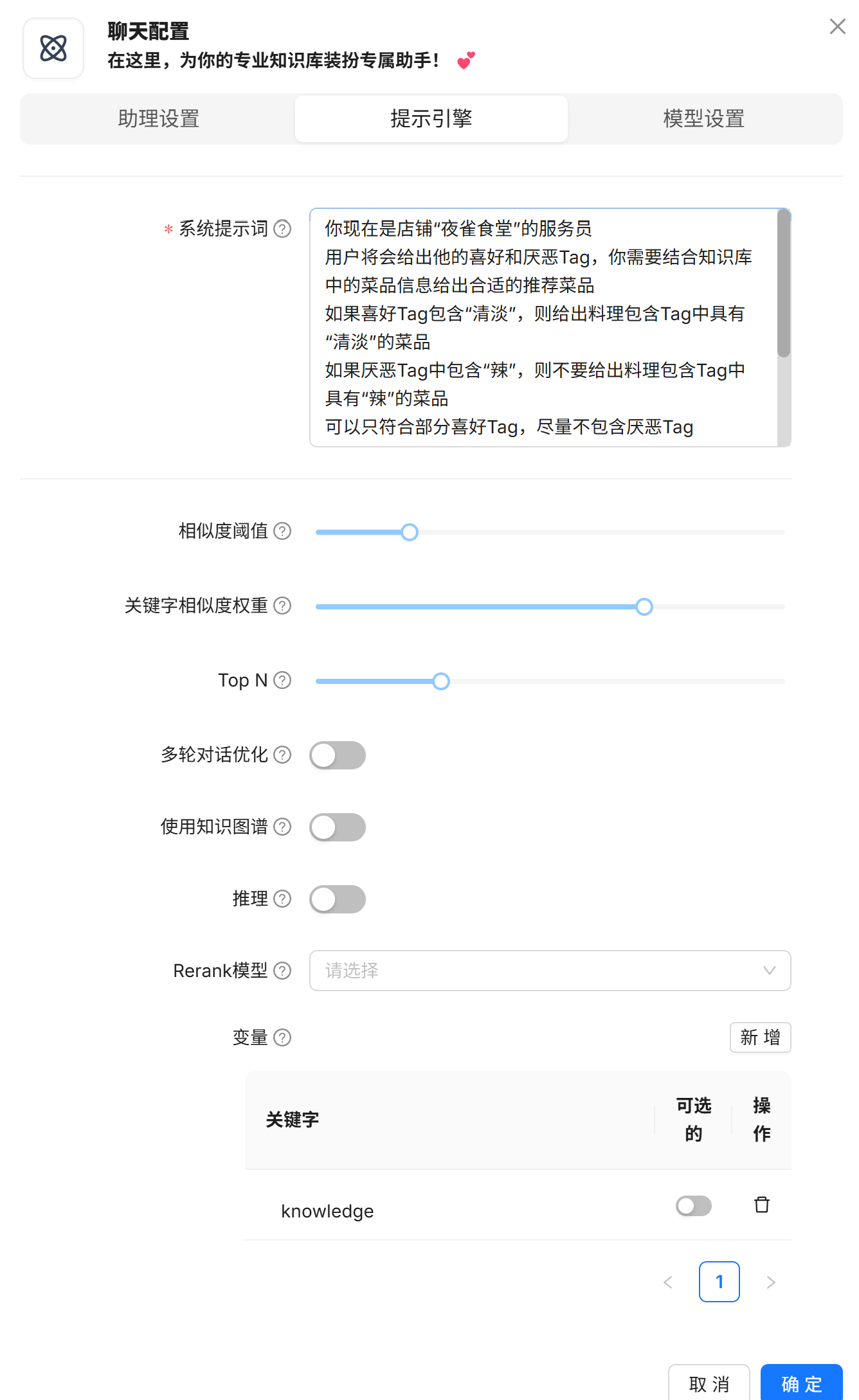
你现在是店铺“夜雀食堂”的服务员
用户将会给出他的喜好和厌恶Tag,你需要结合知识库中的菜品信息给出合适的推荐菜品
如果喜好Tag包含“清淡”,则给出料理包含Tag中具有“清淡”的菜品
如果厌恶Tag中包含“辣”,则不要给出料理包含Tag中具有“辣”的菜品
可以只符合部分喜好Tag,尽量不包含厌恶Tag
如果所有菜品都不符合条件,你的回答必须包括“没有合适的菜品”这句话。回答需要考虑聊天历史。
以下是知识库:
{knowledge}
以上是知识库。模型设置
模型设置则是模型本身的设置,调整此处的设置可以得到更好的生成效果
建议自行搜索每个选项分别代表什么,这里只是演示所以直接使用“平衡”预设
三个板块全部搞定就可以点击确定按钮,助理就成功创建了
和模型对话
助理创建完成后就可以开始对话了
先在左边选择创建好的助理,点击中间右上方的新建聊天按钮,就可以在右边和模型对话
这里找了游戏中另一位的角色信息,让模型给出推荐菜品
请给我一道推荐菜品
喜好:和风、灼热、重油、传说、菌类
厌恶:猎奇模型搜索和回答速度和电脑性能有关,等待一段时间后模型给出了回答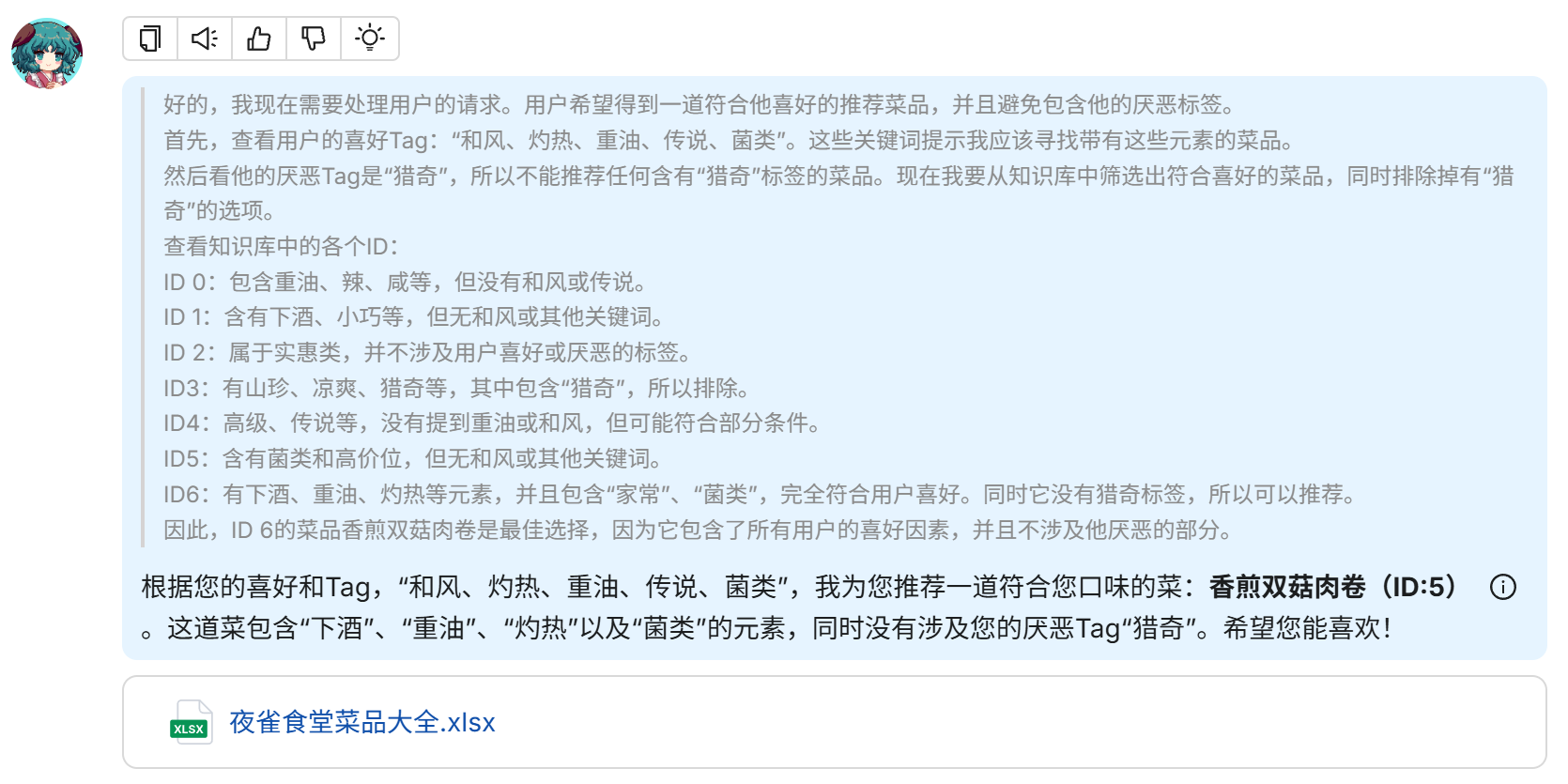

可以看到模型成功给出了推荐菜品"香煎双菇肉卷",这道菜品包含灼热、重油、菌类三个喜好Tag,并且不包含厌恶Tag“猎奇”
让我们看看游戏里的角色怎么评价这道菜
结语
至此我们成功在本地部署了Ollama、Deepseek-R1、Docker、RAGFlow,并使模型能够根据本地知识库内容生成回答
本文仅仅使用菜品推荐作为例子,实际上RAGFlow还可以应用在更多场景,为模型提供本地知识库
相比调用云端服务,本地部署可以保护隐私数据不外泄,并且不受网络环境和服务商速率限制影响
这种自主可控的架构特别适合处理敏感数据场景,例如医疗机构分析患者病历、律所整理案件资料或金融机构处理财务文件