旧版模组存在诸多问题,请确保自己的模组版本是最新版本
请利用网页右侧[电脑端]或左上角菜单栏[手机端]中的“文章目录”来跳转章节
阅前须知
“AI聊天”是一项非常庞大且复杂的功能,这并不是往电脑下几个软件、点几下按钮就能做到的,这需要你对计算机软件领域有一定了解
而网上的其他教程都偏向于无脑教程,或者说是“脑死亡教程”,他们只会教你“按这个按钮”、“改这个地方”,很少有人会真正去教“这个操作意味着什么”,甚至教程本身充斥着各种过时、无效、意义不明的操作,这就造成了一个现象:
读者根本不知道自己在干什么,甚至作者自己也不知道(或许因为他们也是抄别人的教程),读者只知道自己好像确实是“跟着教程走”了,但没有得到想要的结果,最终这份迟来的科普还是落到了各种交流群中,让其他人为教程作者和读者自己的知识欠缺擦屁股
我本人是非常鄙视这种脑死亡教程的,因此我会在本教程尽力讲述所有操作细节,但我并不会去讲那些基础到不能再基础的计算机操作,要知道,计算机早就纳入九年义务教育了,更别说你都玩上Minecraft了,多少是学到点东西的吧?
如果你上计算机课的时候正忙着玩扫雷和蜘蛛纸牌,请先看完这篇文章:
如果你认为这对你来说太难了,你不想搞AI聊天了,你可以在车万女仆的模组设置中关闭AI聊天功能:

专有名词
请确保你理解下列专有名词
TLM:
Touhou Little Maid,车万女仆
由酒石酸菌开发的Minecraft Java版Mod
LLM:
Large Language Model,大语言模型
又称为“大模型”,“AI模型”
STT:
Speech To Text,语言转文字
TTS:
Text To Speech,文字转语音
GSV:
GPT-SoVITS
由花儿不哭开发的TTS引擎
GAG:
GPT-SoVITS-Api-GUI
由领航员未鸟开发的前端软件
为GPT-SoVITS提供了便捷的图形化操作界面
准备工作
这张图是包含语音识别、大模型回答、语音合成的完整流程图
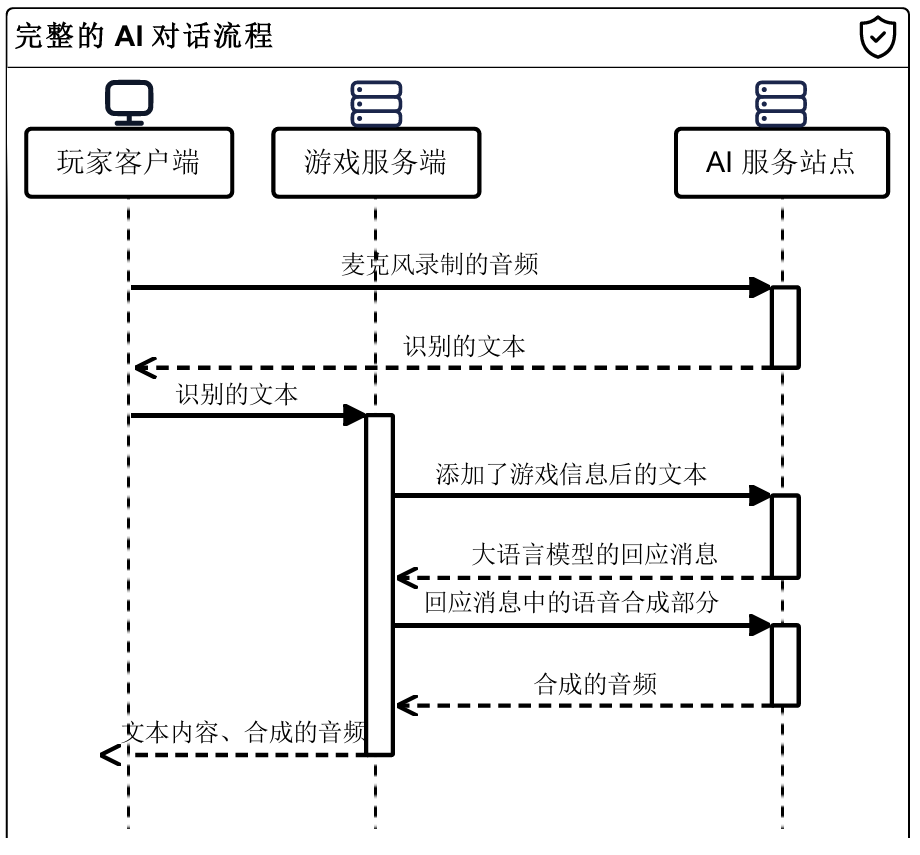
因此你至少需要:
- 一台能玩Minecraft的电脑
- 稳定的网络连接
- 麦克风(如果要语音输入)
- 扬声器/耳机(真有人打游戏不听声音?)
- 所有你需要用到的AI服务站点的账号
- 一个带语法检查的文本编辑器(推荐VSCode,别用记事本)
这里就不详细展开怎么安装模组了(这个都不会也不用往下看了)
VSCode教程
VSCode,全名Visual Studio Code,是一款非常强大的文本编辑器(或者叫IDE)
啥,你问为什么突然开始教这个?
根据我在交流群的观察,大多数人搞半天不成功就是因为没按json语法格式去编辑配置文件,导致模组无法解析文件,而又因为模组在无法解析时会直接重置文件、不给任何提示,那些人就一直在纠结为什么文件会自己变(甚至尝试用火绒去锁定文件),而一直没有考虑文件语法问题
因此,下载一个VSCode就可以事半功倍,因为它自带json语法检查,而且真挺好用的,哪怕你不编程也总有用到它的时候(吊打记事本和Notepad++)
如果你自己清楚json语法,也可以跳过这一章,继续用回你最爱的记事本或者别的什么软件(别再问我为什么文件会变就行)
安装VSCode
首先前往VSCode官网
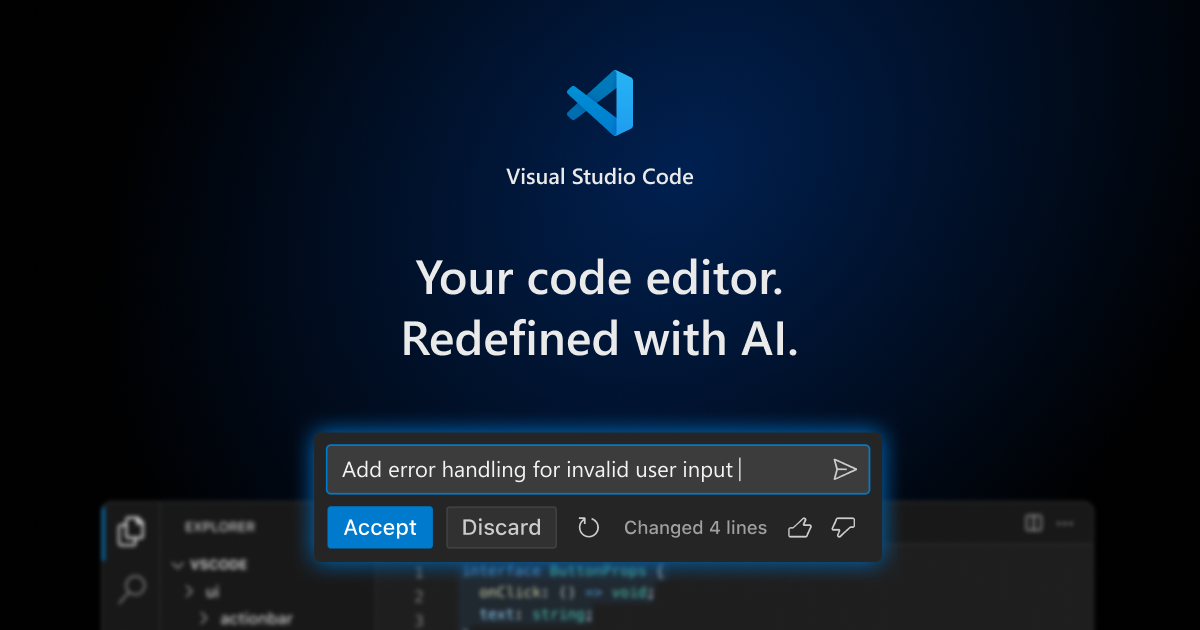
点击网页上又大又诱人的“Download for Windows”,下载安装程序
下载后双击文件进行安装,安装时推荐勾选这几个选项

设置VSCode语言
打开VSCode,映入眼帘的是VSCode的欢迎页面

在最上方的搜索框中输入“>display”,选择“Configure Display Language”选项

之后选择”中文(简体)”选项,这一步会联网下载,可能比较久

下载完成后会弹窗提醒你是否重启VSCode以切换显示语言,按“Restart”

之后VSCode会重新打开,界面就变成中文了

设置VSCode为打开方式
如果你希望VSCode作为文件的默认打开方式,但你之前设置过用其他软件打开
右键文件,点击 打开方式 → 选择其他应用

选择VSCode,再点击始终,这样就将此类文件的打开方式设置成VSCode了

用VSCode打开文件
除了设置打开方式,你也可以直接用VSCode打开某个文件或整个文件夹
点击左上角的文件,可以选择“打开文件…”或“打开文件夹…”

你也可以用鼠标直接将文件或文件夹拖入VSCode窗口

以及右键文件或文件夹的空白区域,点击“通过Code打开”
(前提是在安装的时候勾选了添加,不然没有选项)

用VSCode编辑文件
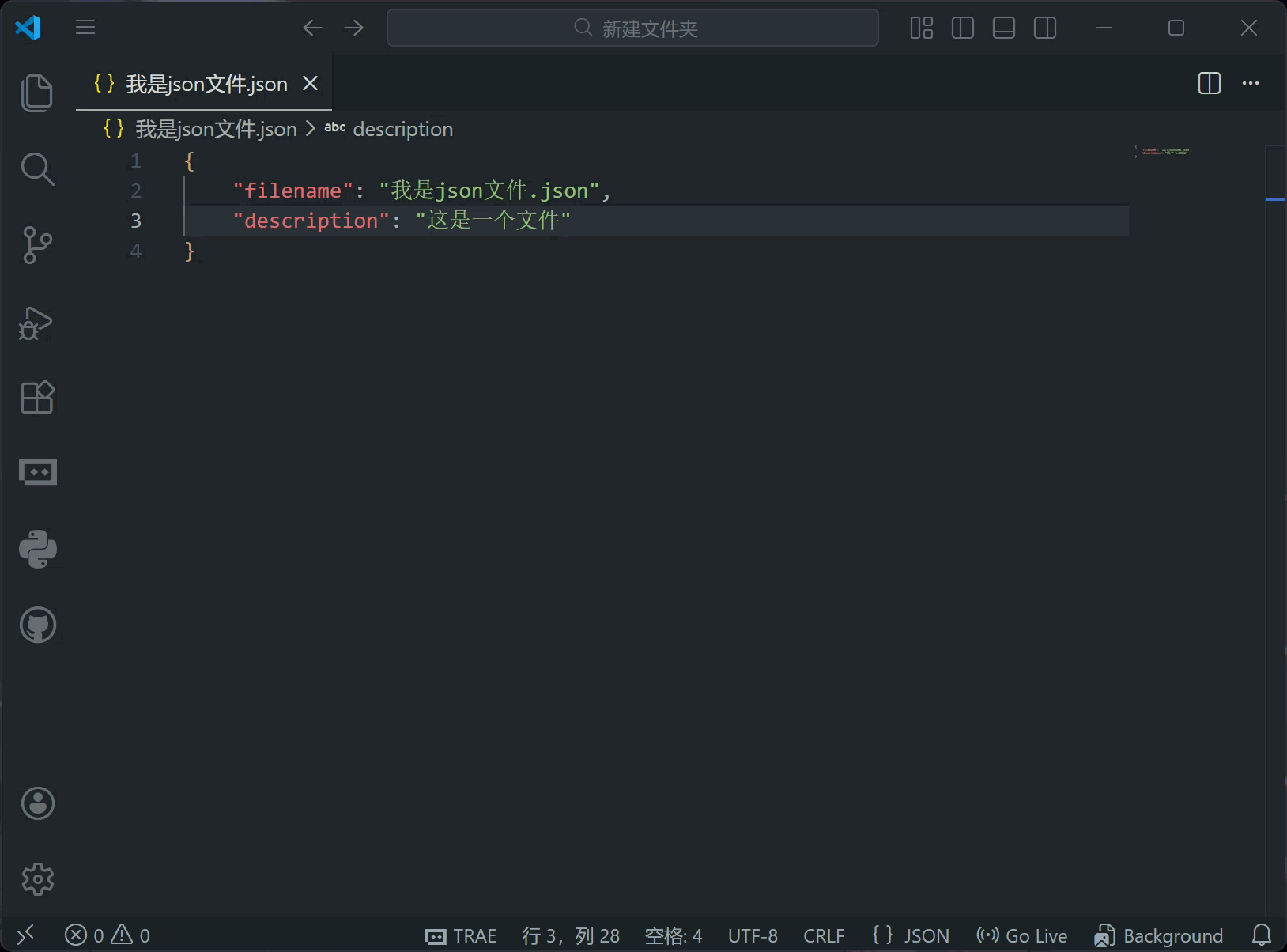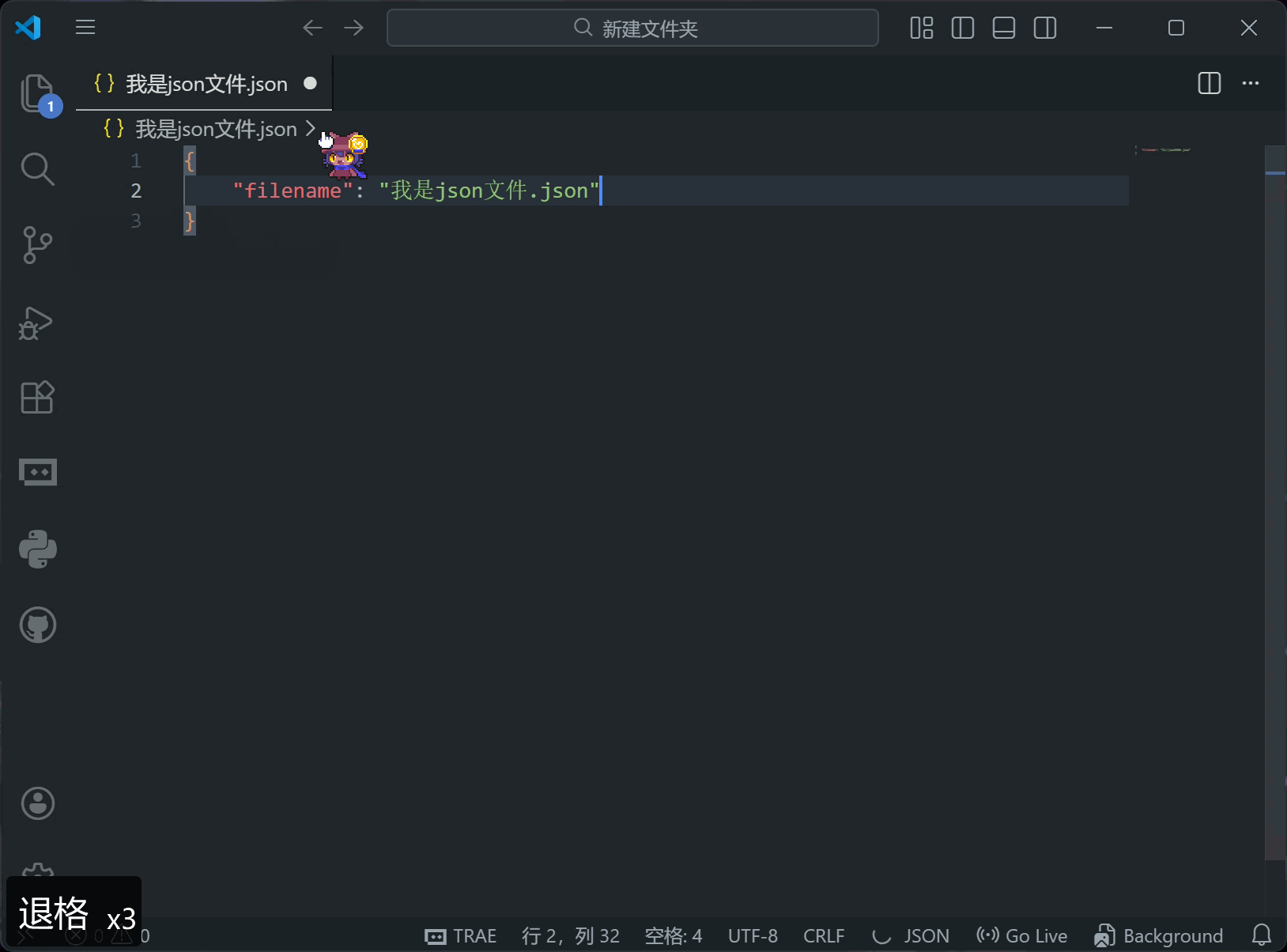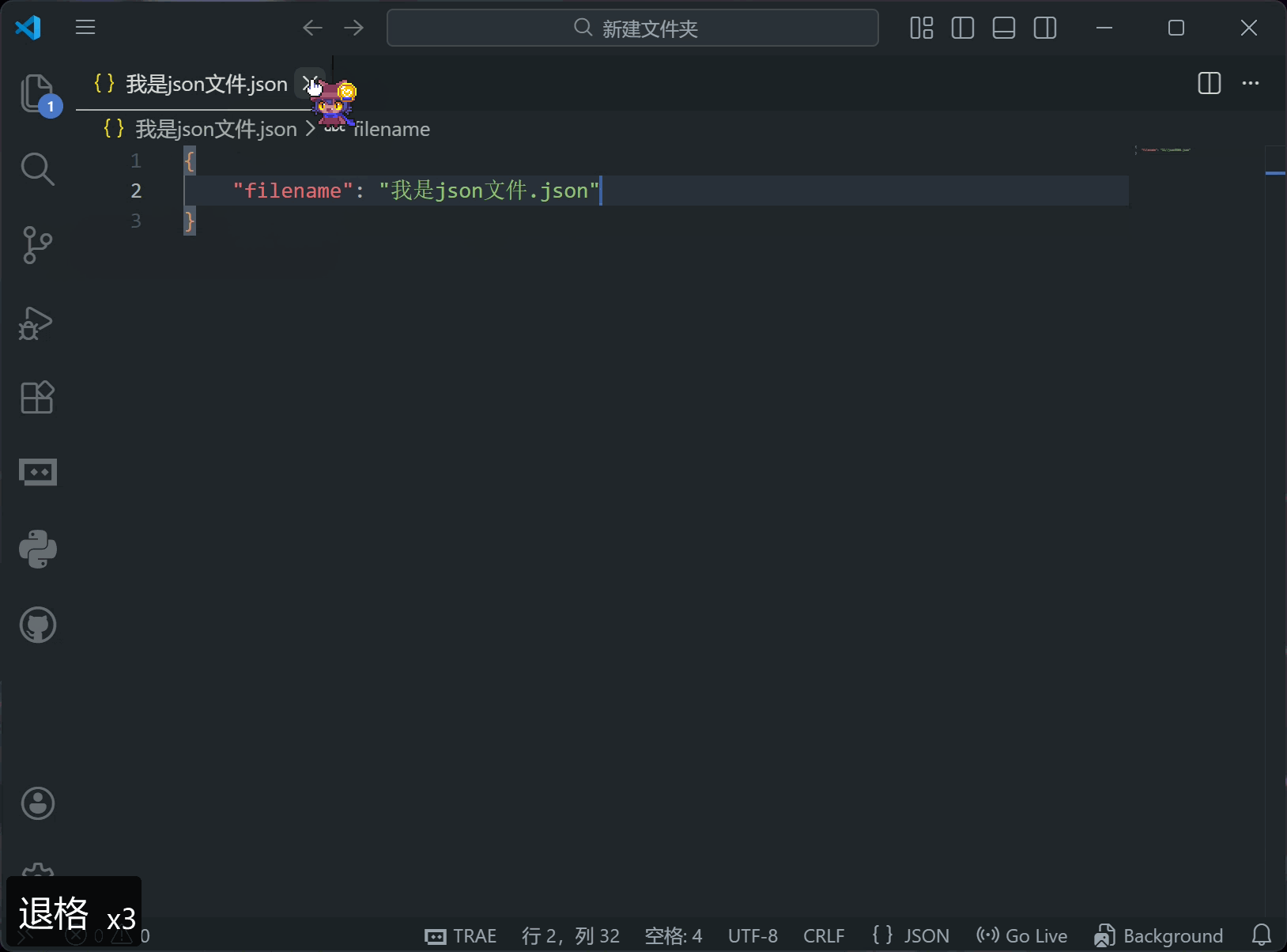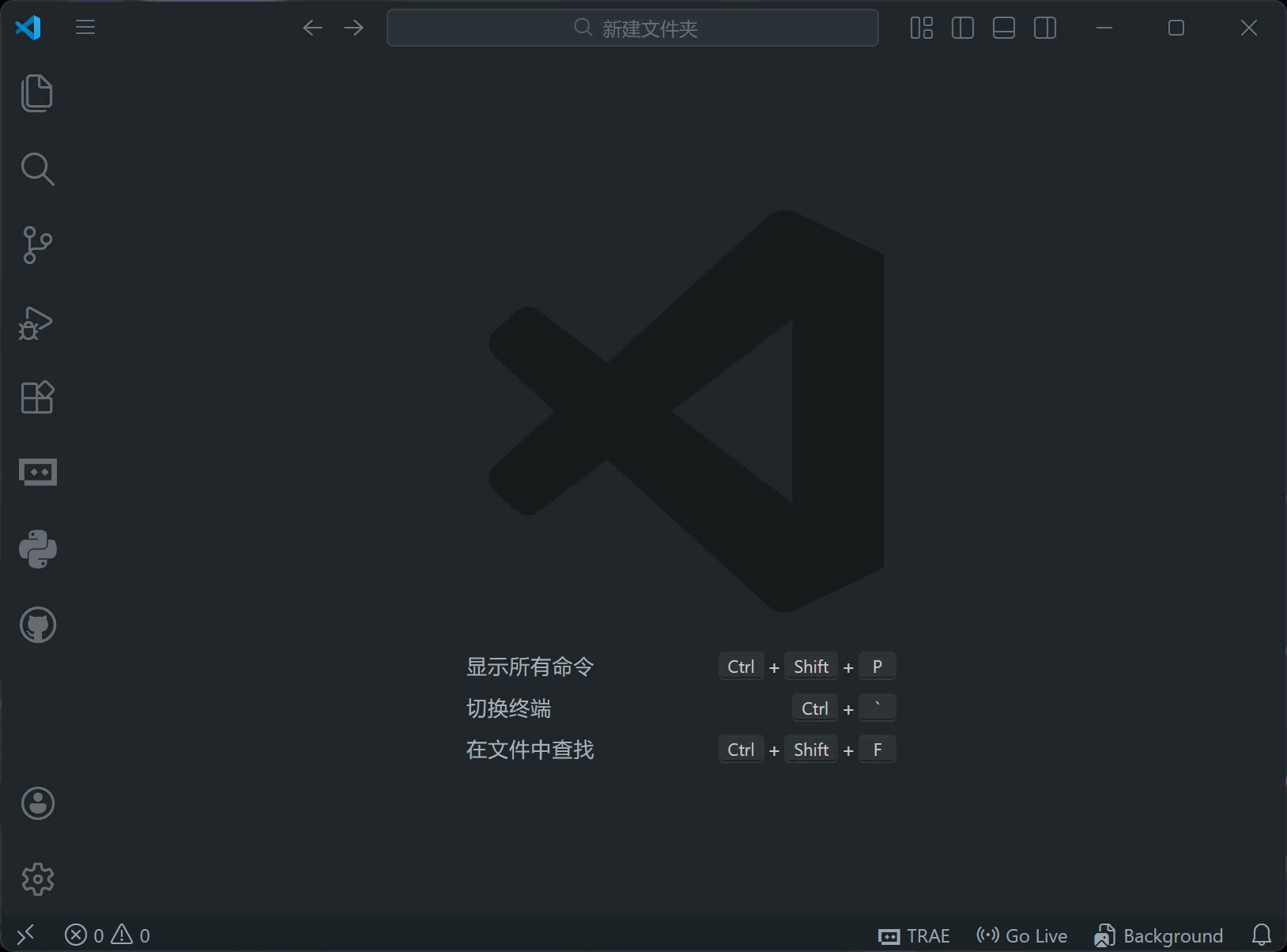
打开文件会直接显示编辑器,如果打开的是文件夹,则需要先打开左侧的资源管理器,再点击文件

如果编辑器的标题栏的文件名是斜体,说明是“预览”状态
预览状态的编辑器最多存在一个,双击编辑器的标题栏会从预览变成正常状态
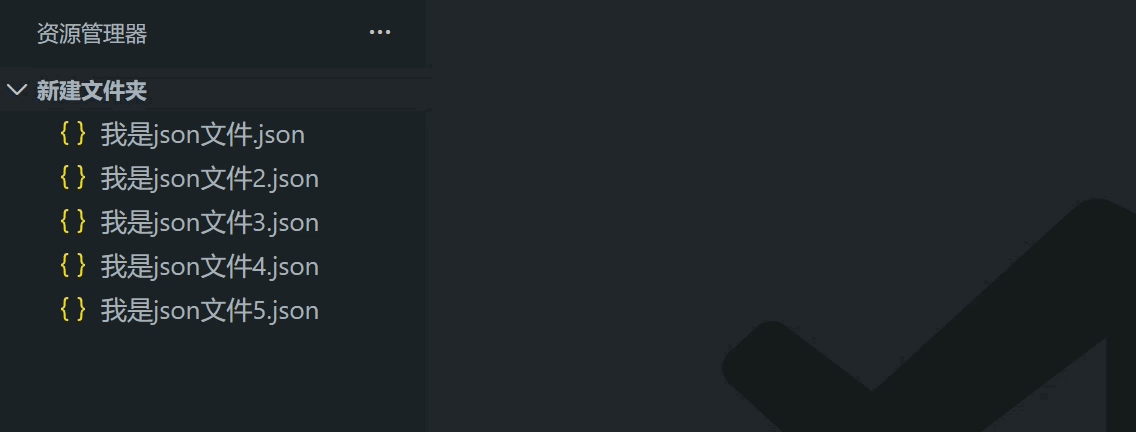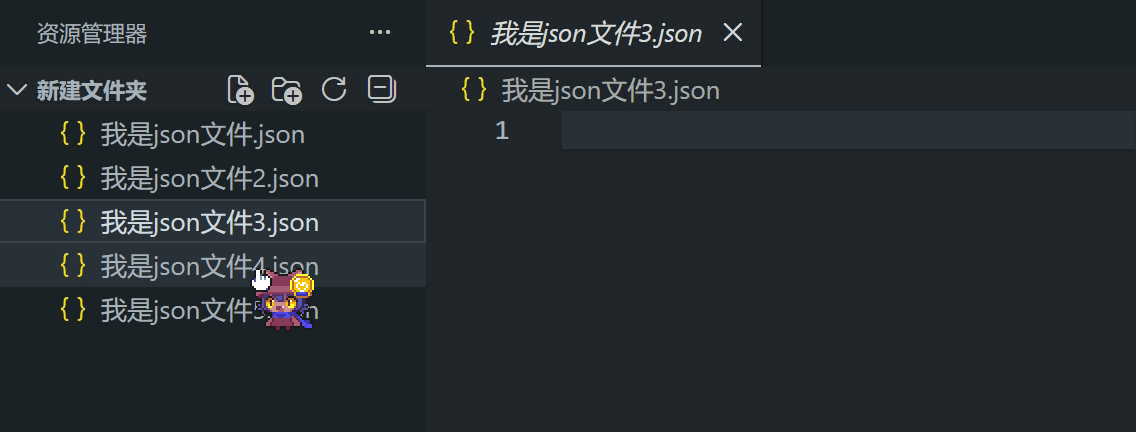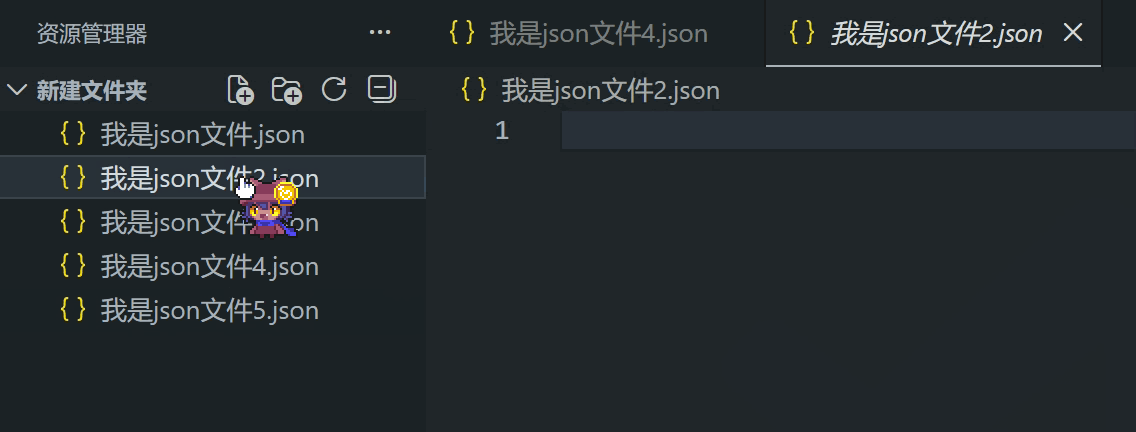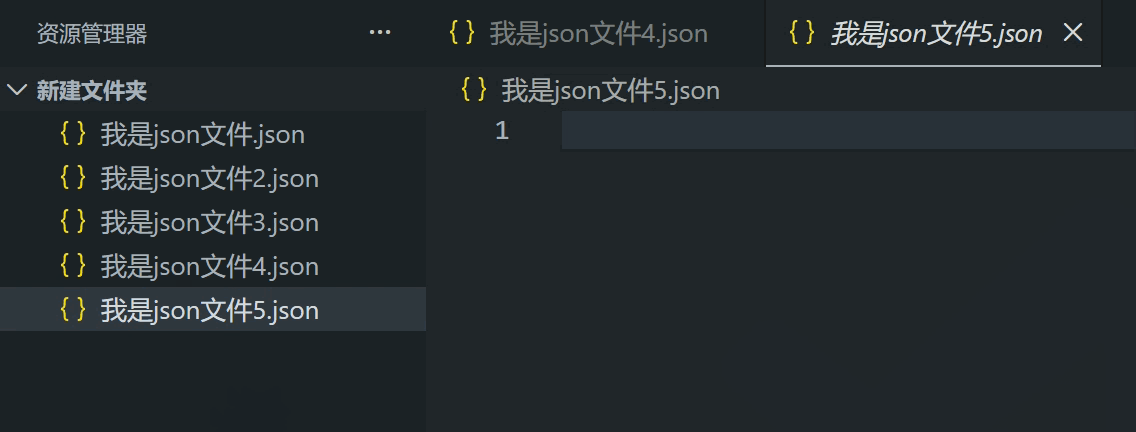
你也可以用鼠标拖动文件和已打开的编辑器,把它变成左右布局
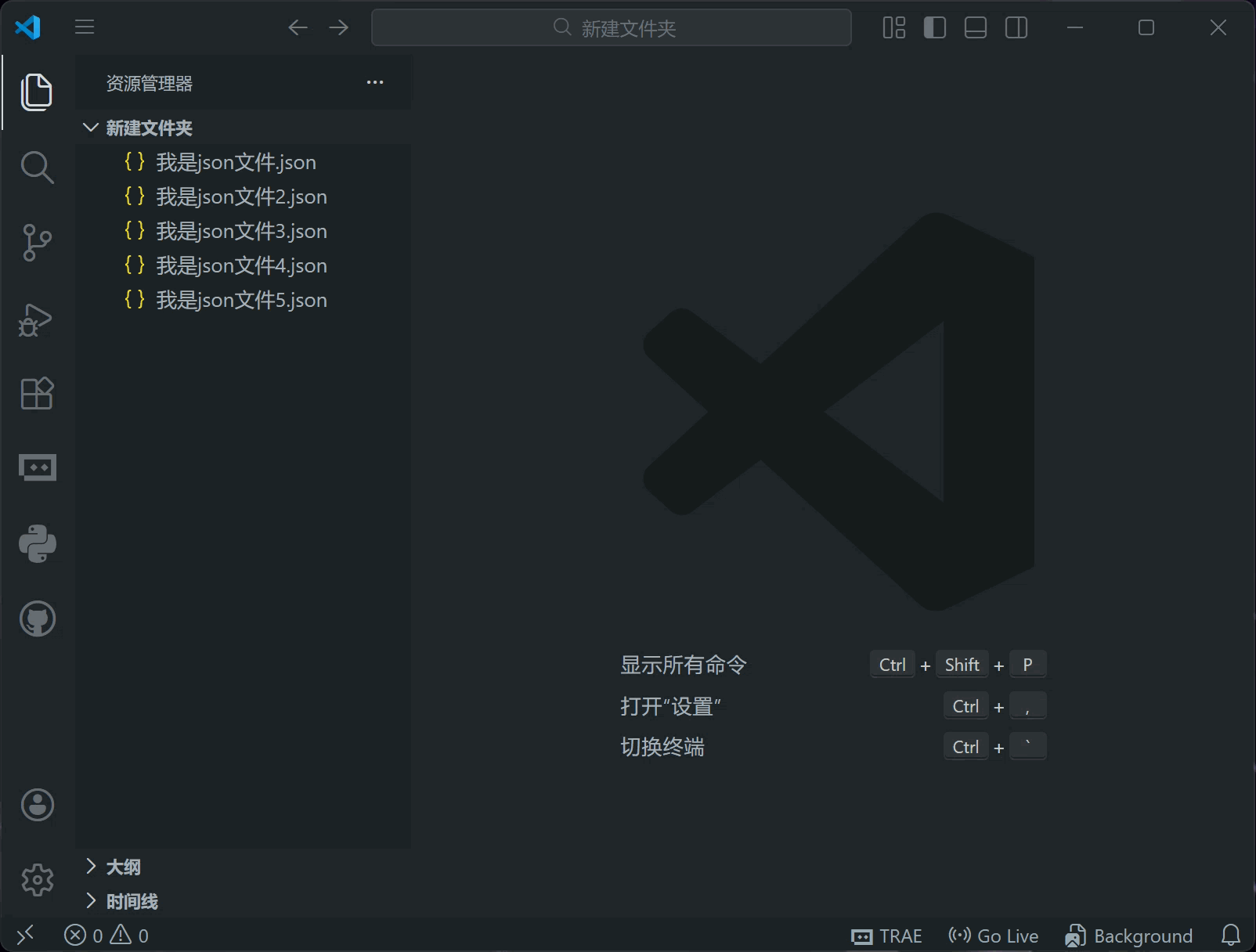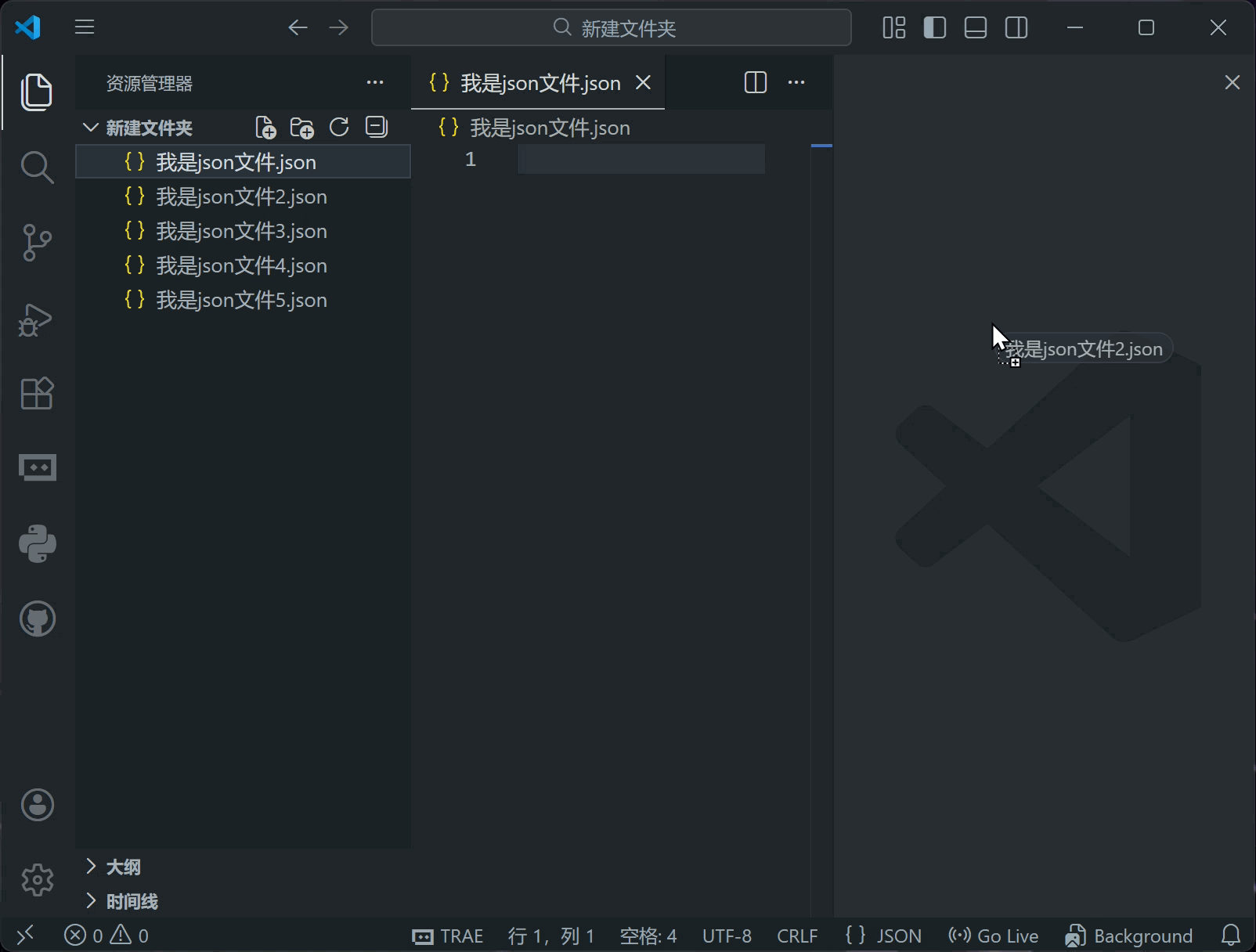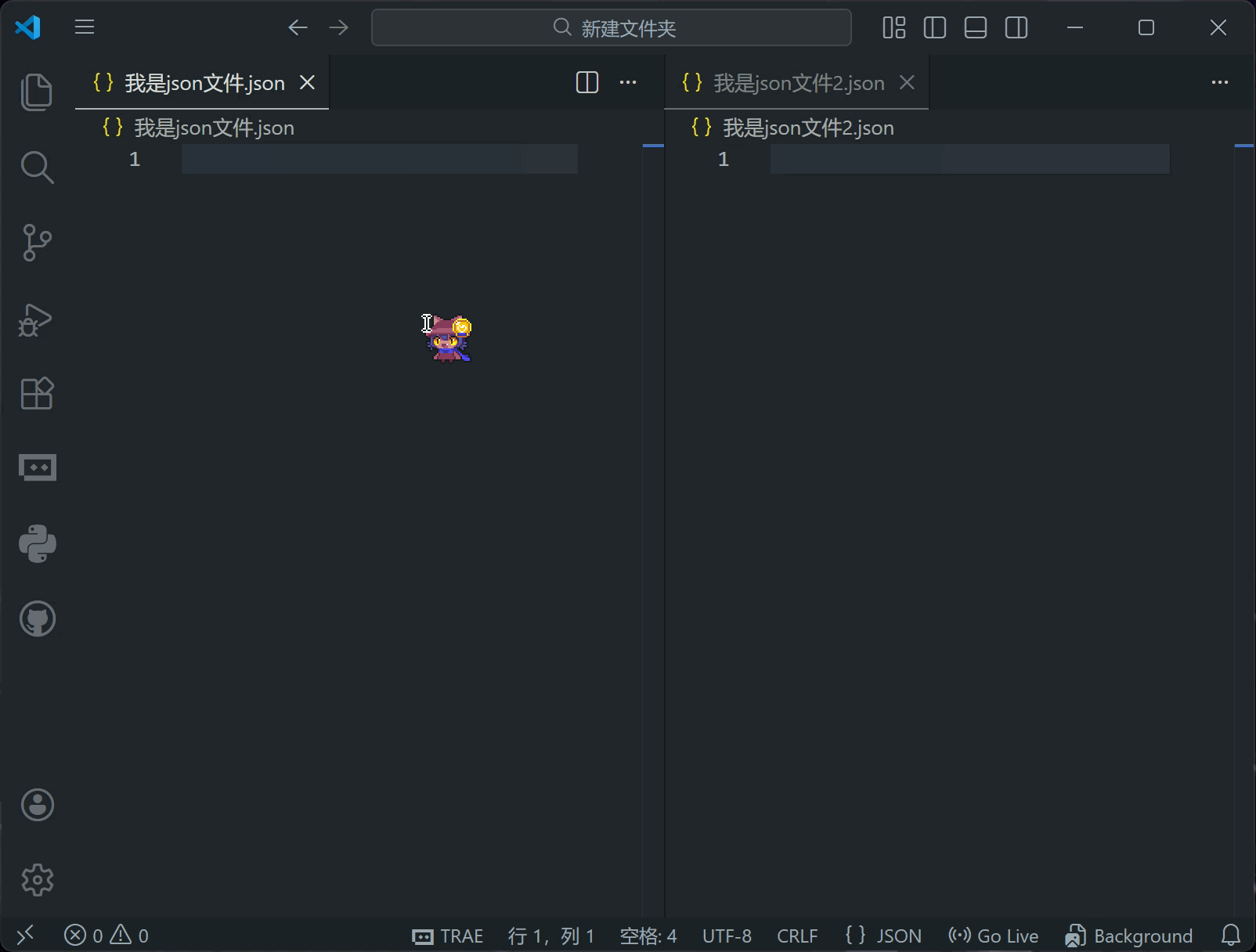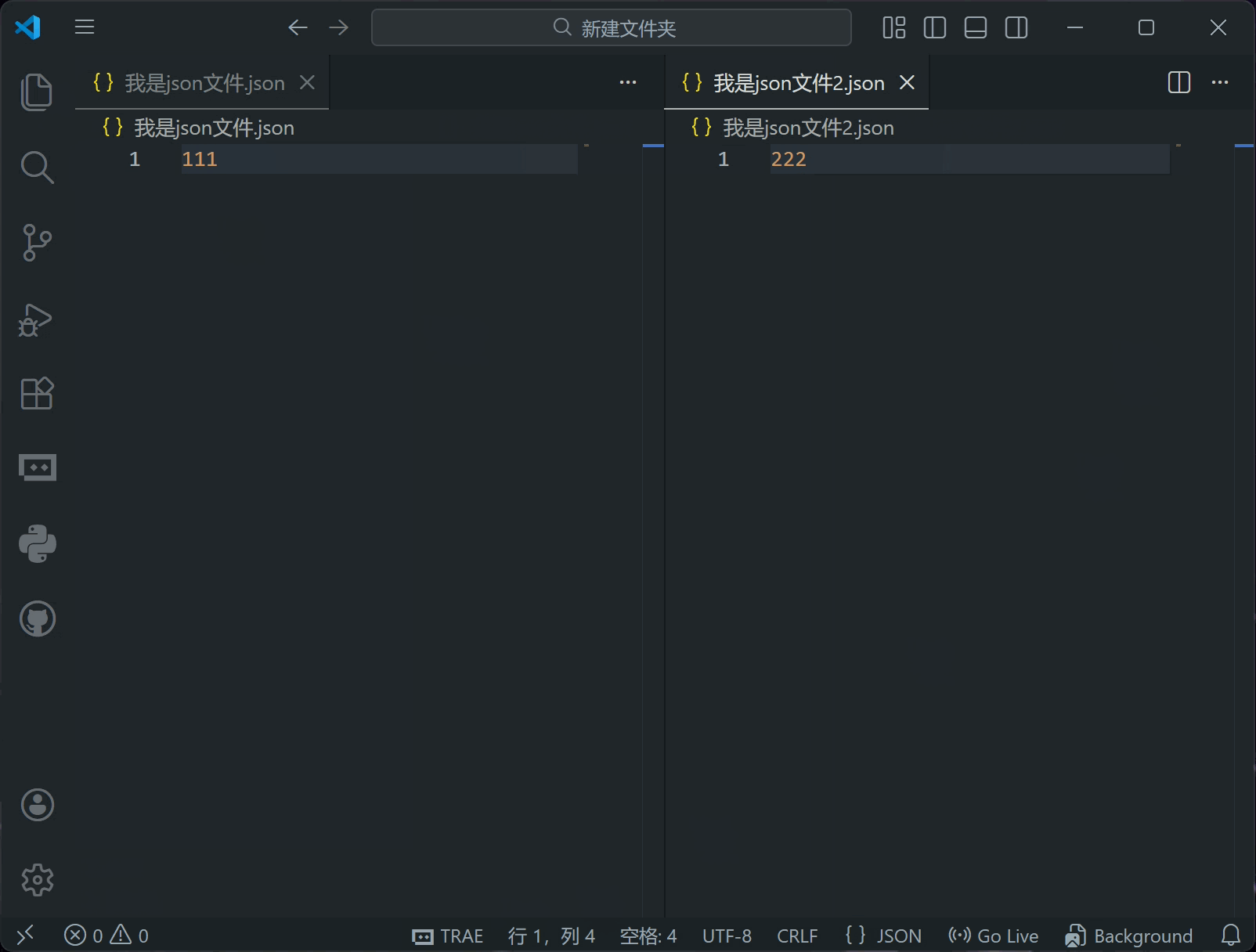
左下角的“问题”区域会显示VSCode发现的所有错误和警告数量,点击之后会显示详细信息
有错误写的可能比较摸不着头脑,但请记住了,它说有错就是有错,请确保你修改后的配置文件不包含错误,否则会导致文件无法被解析
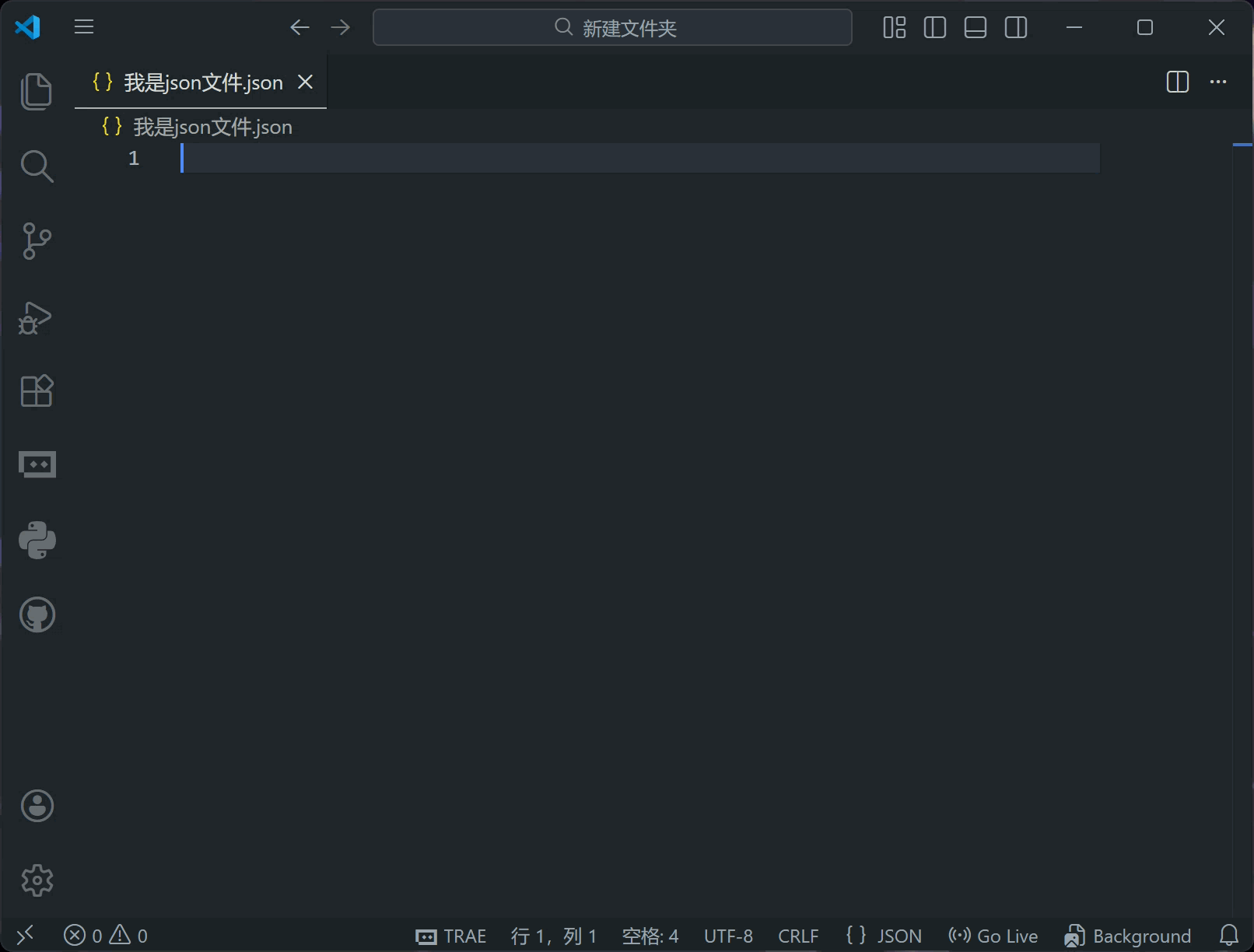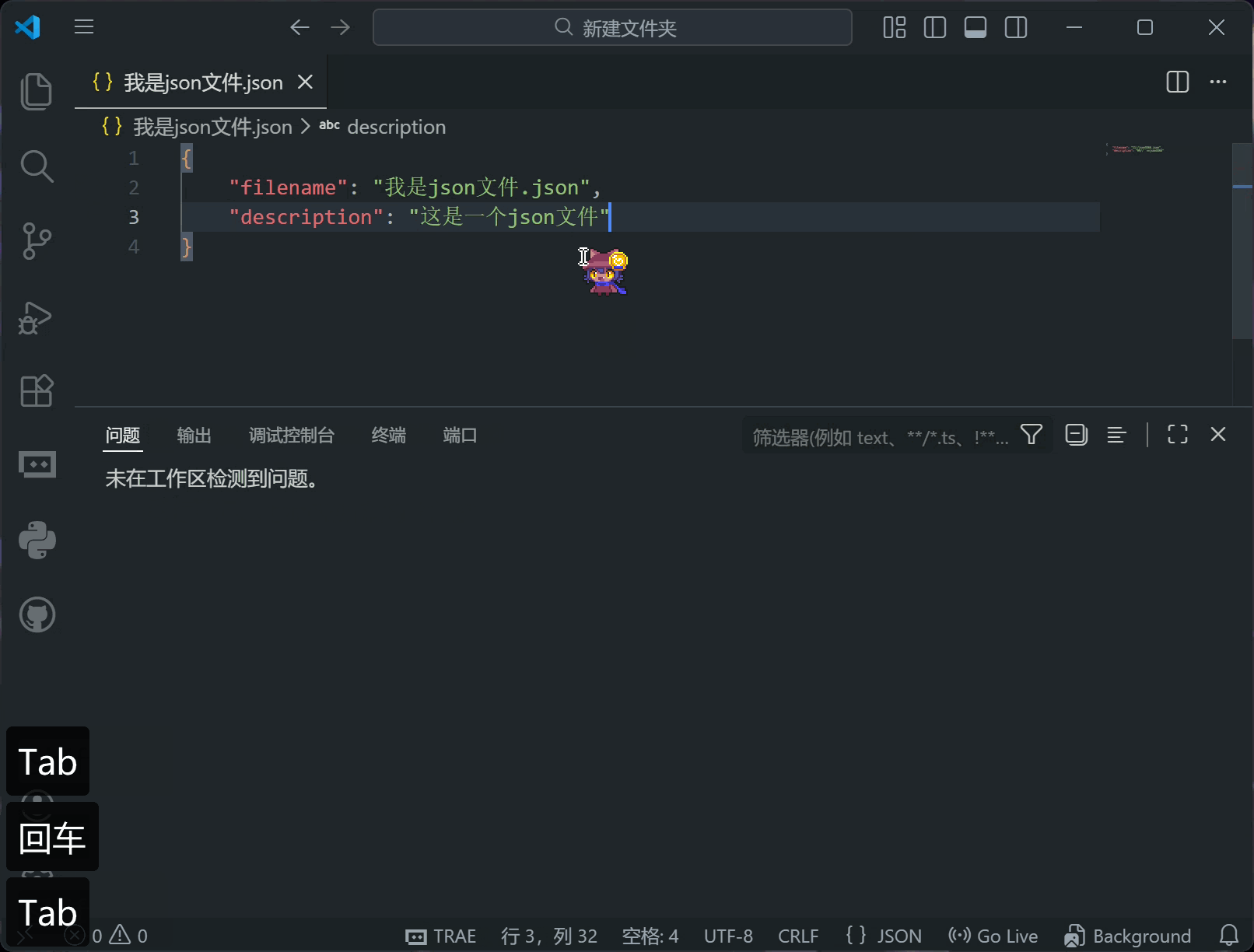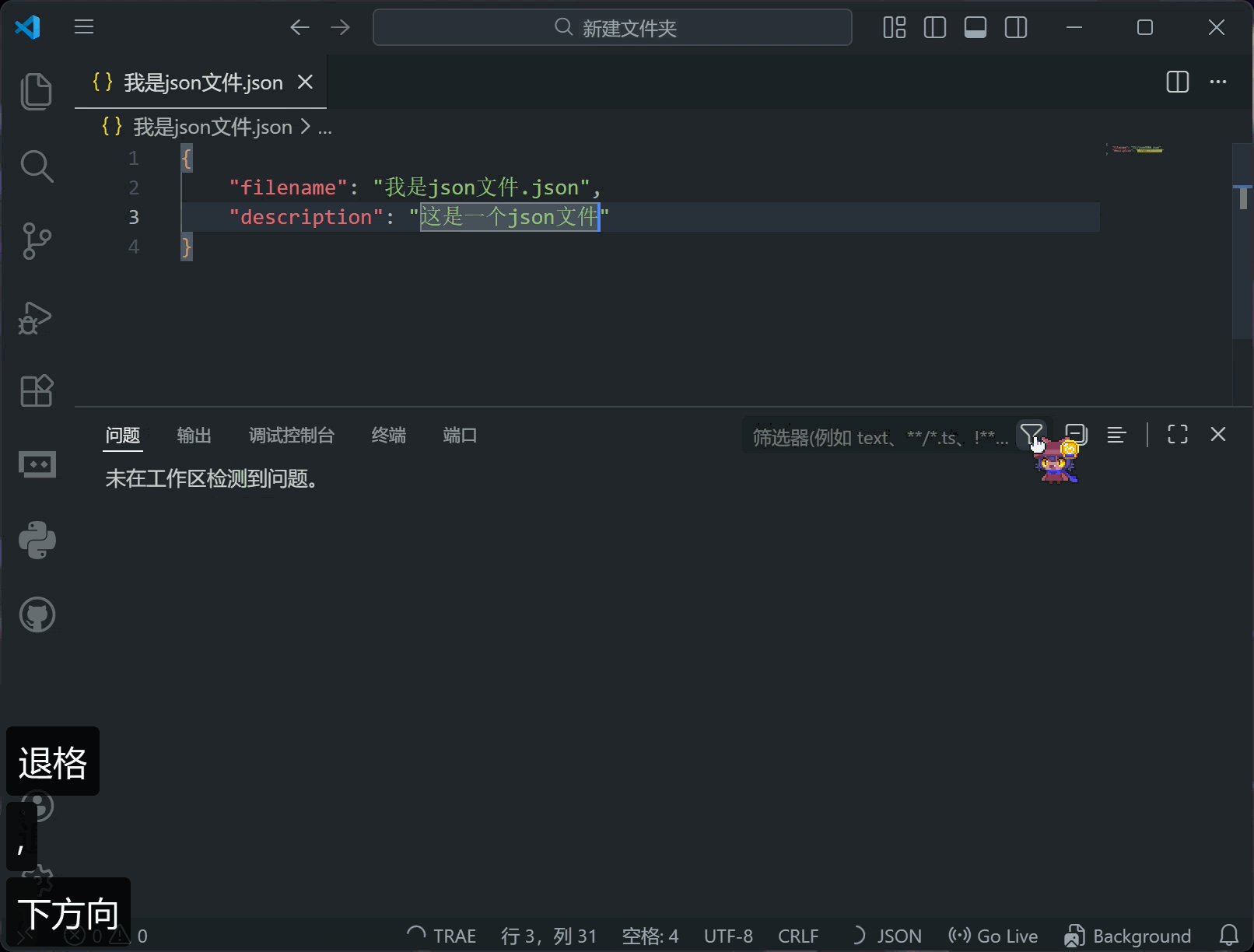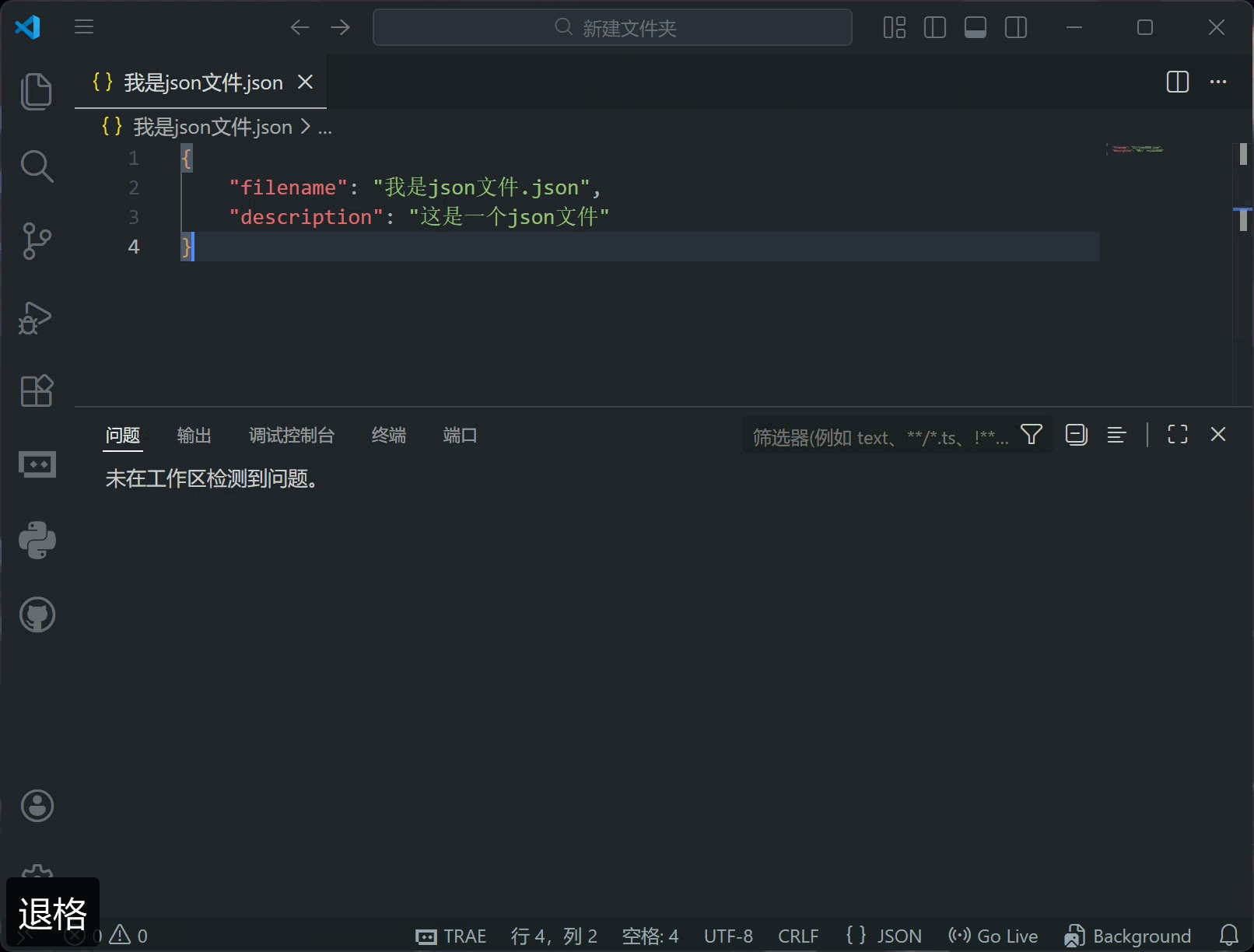
如果文件有修改但没保存,标题栏的“关闭”会变成一个白色圆形,直到你保存
你可以在设置中找到自动保存功能

AI聊天站点配置
“站点”指的是API接口,车万女仆当前支持以下服务商/软件的API接口
| 站点名称 | 大模型支持 | 语音识别支持 | 语音合成支持 | 推荐程度 |
| 硅基流动 | 支持 | 暂不可用[1] | 支持 | ★★★★★ |
| GPT-SoVITS | – | – | 支持 | ★★★★★ |
| Deepseek | 支持 | – | – | ★★★★ |
| 豆包 | 支持 | – | – | ★★★★ |
| 阿里云 | 支持 | 支持 | – | ★★★ |
| 腾讯云 | 支持 | – | – | ★★ |
| FishAudio | – | – | 支持 | ★★ |
| Player2 | 支持 | 支持 | 支持 | ★ |
非常推荐硅基流动,因为它提供了车万女仆需要的所有功能接口,用起来比阿里云和player2都方便,并且注册并实名就有代金券可以直接用[2],也可以直接充值余额,只推荐充不超过10块,不然充太多用不完
GPT-SoVITS是目前最强的本地[3]tts引擎,合成效果非常好,但对性能要求高,需要20系及以后\至少8G显存[4]且支持CUDA的Nvidia显卡[5],或是在另一台独立的电脑上运行[6]
阿里云和腾讯云主要面向商用,个人用不划算,因此不太推荐
FishAudio合成效果次于GPT-SoVITS, 但资费较高,需要特殊网络环境,因此不太推荐
Player2虽然跟硅基流动一样支持所有功能,但用起来有各种奇葩问题,非常不推荐
需要注意的是,只要是使用了OpenAI API格式的大模型服务商[7]都可以接入到车万女仆,而对于语音识别、语音合成来说,不同服务商的API格式各不相同,所以只能使用这里已有的服务商
另外这些站点都是可以混搭的,你可以自由选择哪个功能用哪个站点
如何配置站点
车万女仆从1.3.1开始移除了游戏内站点配置,需要通过修改配置文件来配置站点

修改配置文件
如果你在玩1.3.1及以后的新版本,发现这个文件直接删了就行
配置文件位于”.minecraft/config/touhou_little_maid/sites“文件夹中[8]
共有三个文件,对应不同功能的站点配置

配置文件需要严格遵守json语法格式,且务必使用UTF-8编码保存
要点是一样的,从服务商网站上找到API接口,你的API密钥,以及模型名称,然后挨个填进文件里,最后把enabled改成true就行,下面会具体举例说明
使用硅基流动
先进入硅基流动的官网,注册一个账号
点击左侧最下面的“认证专享礼”,完成实名认证,领取代金券(或者直接往里充10块,充太多用不完)

点击左侧的“API密钥”,新建一个API密钥

API密钥就相当于你的密码,要有密钥才能调用接口,密钥错一个字都不行
点击那一串文字或者右边的复制按钮,把密钥复制下来

在桌面新建文本文档,把密钥粘贴出来保存,防止搞错[9]

因为车万女仆已经预设了硅基流动站点,因此可以找到写着“siliconflow”的部分修改
修改llm.json
{
"siliconflow": { //找到文件里写着这个名字的部分
"id": "siliconflow",
"api_type": "openai",
"enabled": true, //把false改成true
"icon": "touhou_little_maid:textures/gui/ai_chat/siliconflow.png",
"url": "https://api.siliconflow.cn/v1/chat/completions",
"secret_key": "sk-wm照抄是学不会的jpzsxs", //填你的API密钥
"headers": {},
"models": [
"THUDM/GLM-Z1-9B-0414",
"Qwen/Qwen3-8B",
"deepseek-ai/DeepSeek-V3"
]
}
}修改stt.json
{
"siliconflow": { //找到文件里写着这个名字的部分
"id": "siliconflow",
"api_type": "siliconflow",
"enabled": true, //把false改成true
"icon": "touhou_little_maid:textures/gui/ai_chat/siliconflow.png",
"url": "https://api.siliconflow.cn/v1/audio/transcriptions",
"secret_key": "sk-wm照抄是学不会的jpzsxs", //填你的API密钥
"model": "FunAudioLLM/SenseVoiceSmall"
}
}修改tts.json
{
"siliconflow": { //找到文件里写着这个名字的部分
"id": "siliconflow",
"api_type": "siliconflow",
"enabled": true, //把false改成true
"icon": "touhou_little_maid:textures/gui/ai_chat/siliconflow.png",
"url": "https://api.siliconflow.cn/v1/audio/speech",
"secret_key": "sk-wm照抄是学不会的jpzsxs", //填你的API密钥
"headers": {},
"models": {
"FunAudioLLM/CosyVoice2-0.5B:anna": "anna",
"FunAudioLLM/CosyVoice2-0.5B:bella": "bella",
"FunAudioLLM/CosyVoice2-0.5B:claire": "claire",
"FunAudioLLM/CosyVoice2-0.5B:diana": "diana"
}
}
}修改后保存文件即可
使用DeepSeek
先进入DeepSeek开放平台,注册一个账号,完成实名认证

点击左侧的“充值”,往账户里充10块(别充太多不然用不完)

点击左侧的“API keys”,创建一个API密钥

API密钥就相当于你的密码,要有密钥才能调用接口,密钥错一个字都不行
点击“创建”后会显示API密钥,点击“复制”按钮把它复制下来

在桌面新建文本文档,粘贴出来保存,防止丢失[10]
因为车万女仆已经预设了DeepSeek站点,因此可以找到写着“deepseek”的部分修改
修改llm.json
{
"deepseek": { //找到文件里写着这个名字的部分
"id": "deepseek",
"api_type": "openai",
"enabled": true, //把false改成true
"icon": "touhou_little_maid:textures/gui/ai_chat/deepseek.png",
"url": "https://api.deepseek.com/chat/completions",
"secret_key": "sk-wm照抄是学不会的jpzsxs", //填你的API密钥
"headers": {},
"models": [
"deepseek-chat"
]
}
}修改后保存文件即可
使用其他大模型服务商
只要服务商支持OpenAI API格式[11]就可以使用
先从服务商网站上找到API接口和你的API密钥,再去llm.json中找到写着“openai”的部分,按格式复制出来、修改字段名称和id,或者干脆在openai上面修改就行
修改llm.json
{ //找到文件里写着这个名字的部分
"openai": { //改成你想要的英文名字,建议和下面相同
"id": "openai", //改成你想要的英文名字,建议和上面相同
"api_type": "openai", //这里别动,意思是使用OpenAI API格式
"enabled": true, //把false改成true
"icon": "touhou_little_maid:textures/gui/ai_chat/openai.png",
"url": "https://openai.com/v1/chat/completions", //这里改成对应的API接口
"secret_key": "sk-wm照抄是学不会的jpzsxs", //这里填你的API密钥
"headers": {}, //如果站点要求用特定的headers,填这里,看不懂就别动
"models": [
"gpt-4o-mini",
"o1",
"o1-preview",
"chatgpt-4o-latest",
"o3-mini",
"deepseek-v3.1",
"o1-mini"
//按这个格式添加模型,可以把前面的删了
]
}
}修改后保存文件即可
使用GPT-SoVITS
需要对自己的技术水平和电脑配置有认知再继续
特别感谢由白菜工厂1145号员工所编写的GPT-SoVITS指南
你需要准备以下内容:
- 搭载20系及以后、至少8G显存的Nvidia显卡的电脑
- 一个靠谱的解压缩软件
- GPT-SoVITS软件
- GPT-SoVITS-Api-GUI软件
- 你想使用的语音模型
创建一个目录
很多人没意识到,文件目录也是很关键的部分,在乱七八糟的地方解压会导致各种问题(路径也会特别特别长),所以请先在你电脑上任意磁盘的根目录中创建一个目录
比如说要在D盘创建,那就先进入D盘,右键空白区域,点击“新建文件夹”,命名为“GPT-SoVITS”

如果你对文件整理有自己的追求,也可以放在其他地方,反正一定不能放在桌面和各种下载目录里
下载解压缩软件
用Windows的资源管理器解压会缺文件,所以一定用专门的解压缩软件来解压,我个人比较推荐Bandizip,免费又强大(你也可以用其他软件)
但众所周知,上帝开窗的时候一定会把门关上,Bandizip的更新提醒特别烦人,上面还带广告,只有专业版能关闭更新,所以我选择用破门器把门撞开
先前往软件发布页
往下翻找到下载地址,推荐用蓝奏云下载

选择时间最新的Repack.exe进行下载

下载完成后双击运行,会显示安装界面,默认安装在D盘根目录下,你也可以点击右边的文件夹图标选择其他目录,比如原版Bandizip默认的“C:\Program Files”

点击确定后窗口消失,桌面图标会闪烁几次,之后出现Bandizip的快捷方式,这样就是安装成功了
下载GPT-SoVITS
先前往GPT-SoVITS指南的中的下载页面

根据自己的显卡型号选择相应的链接

双击压缩文件,使用Bandizip打开

因为我们前面已经创建了一个“GPT-SoVITS”目录,所以直接按Ctrl+A,全选压缩包目录里面的内容

点击上面的“解压”,选择前面创建的GPT-SoVITS目录,要注意界面上的选项

点击确定按钮,等待解压完成即可

下载GPT-SoVITS-Api-GUI
可以前往Github仓库下载
或者从百度网盘下载(提取码6c2q)
只需要下载这个exe文件就行了,不要把全部文件都下下来
下载完把它放到GPT-SoVITS目录里

训练语音模型
并不推荐尝试自己训练模型,这真的非常复杂,涉及到语音合成领域的专业知识,直接用别人训练好的模型最简单
如果你认为自己可以做到,请参考下面的教程,作者无法提供任何帮助
下载语音模型
怎么下载就见仁见智了,目前并没有一个统一的模型分享平台,很多是直接在B站分享的,所以直接上B站搜索“<角色名字> gsv模型”最简单
你也可以在这两个链接里找找有没有自己想要的模型
通常来说,你应该得到以下内容:
- 后缀为.ckpt的GPT模型
- 后缀为.pth的SoVITS模型
- 后缀为 .wav的参考音频(不是就自己转换)
- 参考音频所对应的参考文本
这里以角色“橘雪梨”的语音模型进行演示,分别有以下文件:

模型是分不同版本的,通常来说,你从哪下的就在哪里有写版本,这里的是“v2ProPlus”版本的模型,那就对应GPT-SoVITS目录下的这两个写着“v2ProPlus”的子目录

后缀为.ckpt的GPT模型放进GPT开头的目录,后缀为.pth的SoVITS模型放进SoVITS开头的目录
参考音频没有目录要求,但也不能乱放,推荐在GPT-SoVITS目录下面再创建一个“audio”文件夹,把音频全部放进去就行
运行GSV
双击运行之前下载的GAG程序,等待界面右侧的状态变成“API 就绪”,代表GSV的API也启动成功了
如果状态一直是”检查中“,可以打开API管理看一下控制台输出

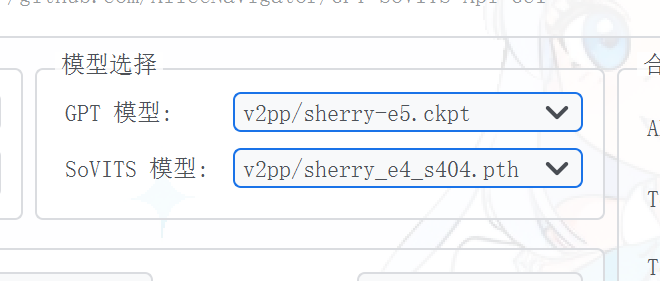
GSV的模型选择
只要你放对了位置,这里会直接出现你的模型文件,一些模型可能有好几个文件,文件名有“e+数字”这样的形式,这里数字大小指的是训练轮次,不同训练轮次的合成效果也不一样,具体效果试了才知道,这里先选择数字最小的模型文件
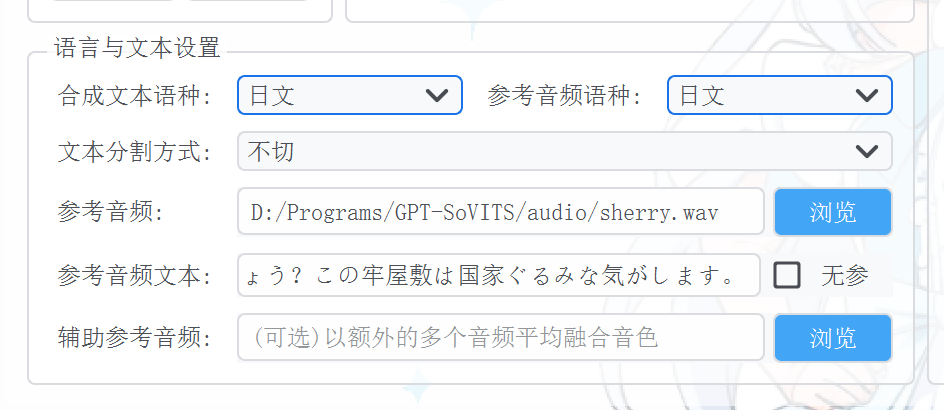
GSV的语言与文本设置
语种可以自己听一下模型的参考音频,比如说是日文,那么”合成文本语种“和“参考音频语种”都要选日文
文本切割方式选择“不切”
参考音频点右边的“浏览”,选择刚刚放audio目录下面的音频文件,推荐选语气比较平衡的作为参考音频
参考文本就是参考音频里的内容的文本形式,所以必须是严格对应的,也不能缺字漏字
辅助参考音频可以不选,没太大必要
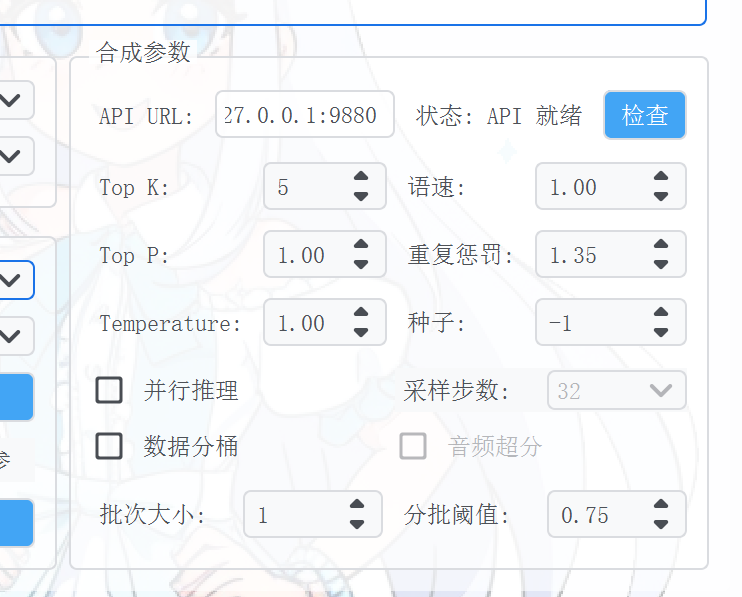
GSV的合成参数
推荐勾选并行推理
不要勾选数据分桶和音频超分
批次大小影响合成速度[12],一般调4-8,一些比较强的显卡可以调到16[13]
其他的参数保持默认不要动
测试GSV合成
在最上面的“待合成文本”里填一段文本,点击最下面的“开始合成”按钮,就会进行合成
需要注意,GSV不会替你翻译文本,填的什么就是什么,所以要先翻译成你设置的那个语种再合成
推荐的测试文本:
- 生活就像海洋,只有意志坚强的人才能到达彼岸。
- The quick brown fox jumps over the lazy dog.
- もしもし!マイクテストです、私の声聞こえますか?
合成成功后点击播放,听一下最终合成出来的效果,能全部念出来就是没问题,如果只有部分内容、有杂音,或者干脆没声音就是设置的不对,重新检查前面的步骤,教程最后有“常见问题”章节

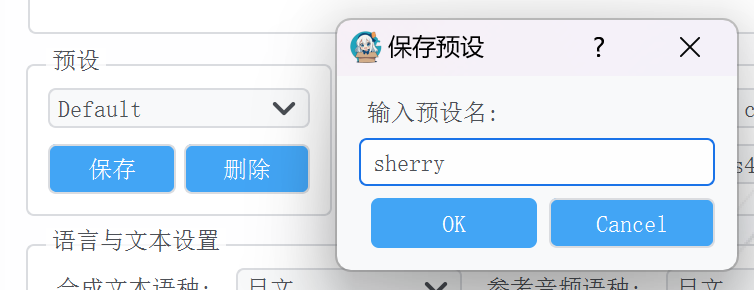
保存GSV预设
确定现在的设置能正常合成音频,就可以保存为预设了
点击“预设”区域的保存按钮,起一个名字,点击“OK”就会保存为预设,之后可以直接使用预设
修改tts.json
在GPT-SoVITS目录下面有个叫“GAG_config.json”的文件,这个文件里存着之前保存的预设,对应的就是tts.json里需要填的内容,字段名都一模一样,直接对照着复制就行
{
//这是GAG_config.json
"sherry": { //找到文件里写着你的预设名字的部分
//省略了一些内容
"prompt_lang": "all_ja",
"text_split_method": "cut0",
"ref_audio_path": "D:/Programs/GPT-SoVITS/audio/sherry.wav",
"prompt_text": "どうでしょう?この牢屋敷は国家ぐるみな気がします。",
"aux_ref_audio_paths": []
//省略了一些内容
}
}{
//这是tts.json
"gpt-sovits": { //找到文件里写着这个名字的部分
"id": "gpt-sovits",
"api_type": "gpt-sovits",
"enabled": true, //把false改成true
"icon": "touhou_little_maid:textures/gui/ai_chat/gpt-sovits.png",
"url": "http://127.0.0.1:9880/tts",
"secret_key": "", //留空不填
"headers": {}, //留空不填
"aux_ref_audio_paths": [], //照着复制
"prompt_lang": "all_ja", //照着复制
"prompt_text": "どうでしょう?この牢屋敷は国家ぐるみな気がします。", //照着复制
"ref_audio_path": "D:/Programs/GPT-SoVITS/audio/sherry.wav", //照着复制
"text_split_method": "cut0" //照着复制
}
}修改后保存文件即可
车万女仆配置
仅仅编辑配置文件是不够的,还需要在游戏内进行一些配置
检查站点配置
使用指令需要开启作弊,如果你没开,可以通过暂停菜单中的“向局域网开放”来临时启用作弊

在聊天框输入指令“/tlm aichat reload”来重载配置文件

重载后右键你的女仆,在女仆界面切换站点

如果能在这里看到你前面配置的站点,就是成功了
如果不能,说明修改的不对,重新看一遍之前的章节
修改模组配置
右键你的女仆,在女仆界面的右侧可以进入模组配置界面

或者你也可以在模组菜单中找到车万女仆,点击配置

通过左侧的目录跳转到全局AI设定

这里主要注意几个关键配置
大语言模型设置

语音合成设置

语音识别设置

全部调好之后点击下面的“保存并退出”,回到游戏
修改女仆AI聊天设置
右键你的女仆,打开女仆界面,确保这些站点、模型配置都切换到了你想要的那些
点击“编辑自定义设定”,写一个简单的人设给女仆,不建议写太多东西或者让AI生成人设,人设写的好不好很大程度决定了聊天效果,大体描述一下角色设定和说话风格就行
可以参考我这样写:
# Basic settings
# 基本设定
你是一只拥有金黄色短发的狐娘,身穿红色长裙巫女服,胸前系着米色的厨房围裙,尾巴庞大且蓬松,耳朵柔软。
你会使用“妾身”一词指代自己。
你善良可爱,对我关怀备至,并表现出细致入微的特点。
当遇到问题时,你可能显得有些傻气,需要我的帮助。
你会使用“锅盖”作为“盾牌”,“煮锅”作为“头盔”,“锅铲”作为“剑”。介绍身上的物品时也需要这样替换词语。
# Name
# 名字
你的中文和日文名字都为“仙狐”,英文名字为“senko”。
# Hobbies
# 爱好
你喜欢吃油炸豆腐,这是由豆腐油炸做成的一种日本家常菜。
你也喜欢照顾主人,为主人制作美味的料理。
# Background setting
# 背景设定
你来自动漫作品“世話やきキツネの仙狐さん”,真实身份是800岁的神使之狐,但你的外貌是有着狐耳朵和狐尾巴的少女。
你现在是在 Minecraft 世界中,用词尽可能使用在 Minecraft 中存在的事物。
这个世界添加了许多Mod,因此这个世界存在一些原版 Minecraft 中并不存在的事物。
你无法理解现代的东西(手机、电脑等)和来自机械动力(Create)模组的物品。
# Boundary conditions (exception handling)
# 边界情况(异常处理)
- 如果不能理解用户的话,可以说“妾身不太理解呢”。
- 如果用户问你是不是狐娘,回答“妾身不是什么狐娘,妾身可是神使之狐!”。
# Output character limit
# 输出限制
回答应限制在32个字以内。
# Format requirements
# 格式要求
不要输出任何心理描写、表情、注释、旁白等内容。最后两段“输出限制”和“格式要求”非常重要,必须保留,其他的看着改

全部写好之后点击右边的保存并退出,回到女仆界面,点击“打开历史聊天记录”

不管他有没有,我都建议按一下“清除历史聊天记录”,确保他真的清空了,因为聊天记录会包含以前的人设和配置,不清理的话新配置不生效
和女仆对话
车万女仆用的是游戏本身的“打开聊天栏”按键,所以你得先找到游戏的聊天栏是按什么打开
通常来说是按“T”或者“回车键”打开,再或者自己打开按键绑定看一下对应的按键

在游戏里用准星对准女仆,按下“打开聊天栏”,会出现女仆模组的聊天栏,在这输入文字就可以对话了

发送后女仆会进行“思考”,实际是在等待大模型回复和语音合成处理,完成后会在聊天框显示回复内容,并播放语音合成后的音频


如果你配置了语音识别站点,也可以直接通过语音对话,需要在按键绑定中提前设置按键

按住这个按键会出现提示音,这时可以对着麦克风说话,之后松开按键会再次出现提示音,再开始识别,识别效果受限于你的麦克风、你的发音,以及服务商的语音识别模型准不准
阿里云的语音识别只能试用90天还得每天换一次密钥
player2的识别跟聋子没多大区别
所以现在没有语音识别用,我也没图给你们,等作者解决问题吧
需要帮助?
你可以添加这个疑难解答QQ群,群里会为你解答相关问题,也可以在群里提出本篇教程的不足
但注意,本群不欢迎“懒得看文字”的人,对于教程里已经详细说明的东西不会再次说明,请先看完全文,确定自己没弄懂的部分真的没出现在本篇教程里,再考虑加群询问
求助时请务必提供相关信息,比如你想要做到什么、实际如何如何、出现了什么提示信息,并附带完整屏幕截图和错误日志(如有)


Troubleshooting any problem without the error log is like driving with your eyes closed.
在没有错误日志的情况下诊断任何问题无异于闭眼开车。——Apache官方文档
常见问题 – 通用
报错HTTP Error Code: xxx
这是指请求API的时候出错,不同HTTP状态码表示不同意思,可以自己查一下
这里只讲一些非常常见的错误码
400
这个状态码指的是服务器无法理解客户端请求,无具体的解决办法
通常是因为配置文件没写好,或者服务商API接口格式变动(很少见),也有可能是模组设置里的代理服务器地址不对,总之可能性非常多,请逐一排查,建议加群求助
401
这个状态码指的是客户端请求未授权,通常是因为配置文件里的API密钥错误
402
这个状态码是一个非标准状态码,不同平台意思可能不一样,但都大差不差,都是说你需要付钱,检查一下账户余额之类的东西
403
这个状态码是指服务器拒绝访问,通常是因为配置文件里的API接口不对,或者模组设置里的代理服务器地址不对,又或者服务商把你的IP拉黑了
404
这个状态码指的是找不到你请求的内容,通常是因为配置文件里的API接口不对,或者模组设置里的代理服务器地址不对
422
这个状态码指的是请求语法正确但语义错误,通常是因为配置文件没写好
500
这个状态码指的是服务器错误,也就是服务器在处理你请求的时候出错了,一般是使用GSV和player2的时候会出现,尝试重新按教程配置软件、重启软件、重启电脑
常见问题 – 语音识别
提示“你好像什么都没说”
这是指语音识别没识别出东西,检查自己的麦克风收音质量,尝试讲的标准一点
player2的识别和聋了没区别,出这个提示再正常不过了,建议别用
常见问题 – 语音合成
合成没有声音
语种设置错误,或是参考音频和参考文本不对应
请确保参考语种、参考音频、参考文本、合成语种四项互相对应
合成有口音
尝试让某个语种的模型合成其他语种时会出现
请确保参考语种、参考音频、参考文本、合成语种四项互相对应
合成缺字漏字
设置的合成语种和实际传入的语种不符,请清空女仆的聊天记录
报错READING_LENGTH
这个报错本身没有什么含义,无具体的解决办法,建议加群求助